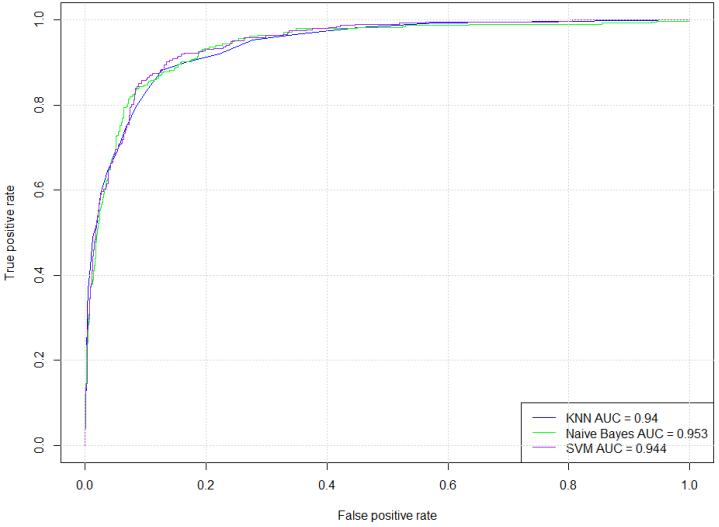
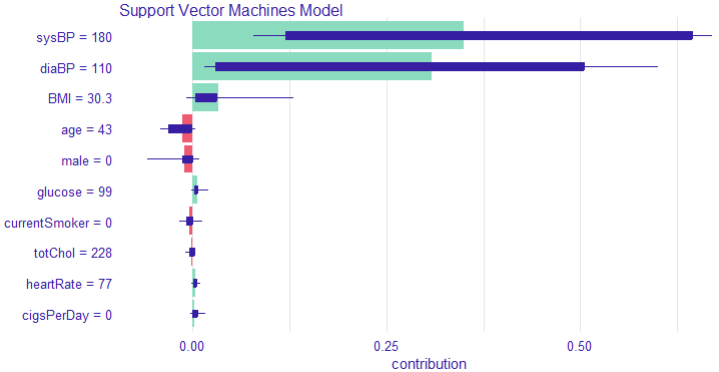
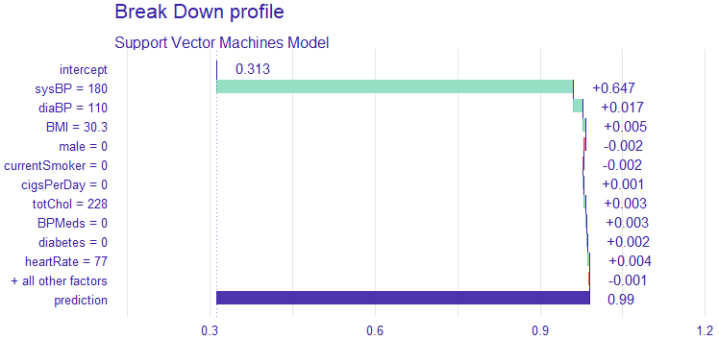
Hypertension is a major public health challenge globally, often undiagnosed until severe complications arise, highlighting the critical need for early and accurate risk prediction methods. Despite advances in machine learning (ML), many models remain black boxes, limiting clinical trust and adoption. This study addresses these gaps by evaluating and interpreting three ML classifiers—Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Naïve Bayes—for hypertension risk prediction, emphasizing both predictive performance and explainability. Using a comprehensive dataset of 4,187 participants, demographic and clinical factors, including age, gender, smoking status, blood pressure, BMI, glucose levels, and medication use, were analyzed. Descriptive statistics revealed significant differences between the at-risk and no-risk groups, particularly in terms of age, blood pressure, cholesterol levels, and diabetes prevalence. Chi-square and Welch's t-tests confirmed these distinctions (p <.001), underscoring the validity of the models' inputs. Model evaluation showed SVM as the most balanced classifier with an accuracy of 88.13% (95% CI [86.22%, 89.86%]) and substantial agreement (kappa = 0.7153). It achieved strong sensitivity (92.66%) and specificity (77.78%), alongside a favorable F1-score (0.9157), indicating robust true positive detection while minimizing false positives. KNN demonstrated high sensitivity (94.69%) but lower specificity (69.25%), with moderate overall accuracy (86.95%). Naïve Bayes, though highly sensitive (99.21%), suffered from poor specificity (34.63%), suggesting a high false-positive rate and imbalanced classification. McNemar's test indicated balanced errors only for SVM (p = 0.1036). Receiver Operating Characteristic (ROC) analysis revealed excellent discrimination for all models, with Naïve Bayes achieving an AUC of 0.953; however, this did not translate into practical reliability due to error imbalance. Explainable AI techniques, specifically SHAP values, elucidated key predictors in SVM, notably systolic and diastolic blood pressure, BMI, and heart rate, enhancing interpretability and stakeholder trust. According to the study, SVM offers the best trade-off between accuracy and interpretability for predicting hypertension risk. Integrating explainable ML models into clinical practice can improve early diagnosis, guide interventions, and inform health policies, supporting ethical, transparent, and effective AI-driven healthcare.
| Published in | American Journal of Artificial Intelligence (Volume 9, Issue 2) |
| DOI | 10.11648/j.ajai.20250902.17 |
| Page(s) | 154-166 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Hypertension, Machine Learning, Support Vector Machine, Explainable AI, Risk Prediction, SHAP Values
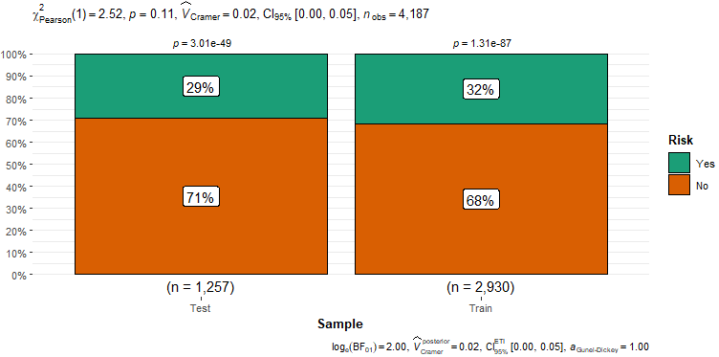
Sample | Risk | Total | |
|---|---|---|---|
No | Yes | ||
Test | 890 | 367 | 1257 |
70.8% | 29.2% | 100% | |
30.8% | 28.3% | 30% | |
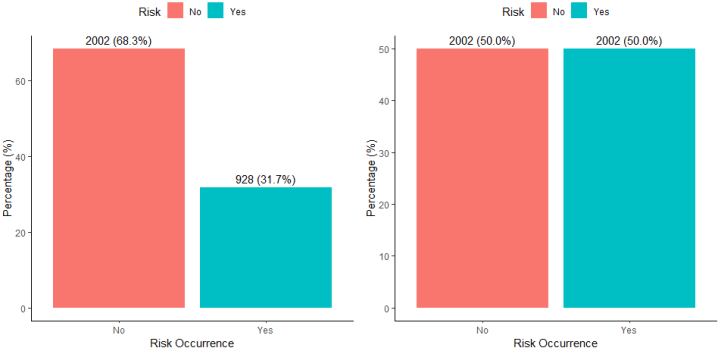
Train | 2002 | 928 | 2930 |
68.3% | 31.7% | 100% | |
69.2% | 71.7% | 70% | |
Total | 2892 | 1295 | 4187 |
69.1% | 30.9% | 100% | |
100% | 100% | 100% | |
χ2=2.409 · df=1 · &phi=0.025 · p=0.121 | |||
Variables | N | Mean | SD | Median | Skew | Kurtosis | SE |
|---|---|---|---|---|---|---|---|
Gender | 4187 | 1.4311 | 0.4953 | 1.0000 | 0.2782 | -1.9231 | 0.0077 |
Age | 4187 | 49.5307 | 8.5559 | 49.0000 | 0.2333 | -0.9867 | 0.1322 |
Current Smoker | 4187 | 1.4949 | 0.5000 | 1.0000 | 0.0205 | -2.0001 | 0.0077 |
Cigarettes Smoked Per Day | 4187 | 9.0165 | 11.8784 | 0.0000 | 1.2471 | 1.0358 | 0.1836 |
Blood Pressure Medications | 4187 | 1.0296 | 0.1695 | 1.0000 | 5.5475 | 28.7815 | 0.0026 |
diabetes* | 4187 | 1.0256 | 0.1578 | 1.0000 | 6.0109 | 34.1393 | 0.0024 |
Total Cholesterol | 4187 | 236.6528 | 44.2228 | 234.0000 | 0.8794 | 4.2823 | 0.6834 |
Systolic Blood Pressure | 4187 | 132.2917 | 21.9829 | 128.0000 | 1.1454 | 2.1766 | 0.3397 |
Diastolic Blood Pressure | 4187 | 82.8911 | 11.8785 | 82.0000 | 0.6969 | 1.2258 | 0.1836 |
BMI | 4187 | 25.8035 | 4.0672 | 25.4200 | 0.9794 | 2.6944 | 0.0629 |
Heart Rate | 4187 | 75.8767 | 12.0535 | 75.0000 | 0.6471 | 0.9030 | 0.1863 |
Glucose Level | 4187 | 81.9584 | 22.9038 | 80.0000 | 6.5269 | 64.7770 | 0.3540 |
Hypertension Risk | 4187 | 1.3093 | 0.4623 | 1.0000 | 0.8249 | -1.3198 | 0.0071 |
Characteristic | N | Overall | No | 95% CI | Yes | 95% CI | p-value2 |
|---|---|---|---|---|---|---|---|
N = 4,1871 | N = 2,8921 | N = 1,2951 | |||||
male | 4,187 | 0.6 | |||||
Female | 2,382 (57%) | 1,652 (57%) | 55%, 59% | 730 (56%) | 54%, 59% | ||
Male | 1,805 (43%) | 1,240 (43%) | 41%, 45% | 565 (44%) | 41%, 46% | ||
age | 4,187 | 49.53 (8.56) | 47.79 (8.16) | 47, 48 | 53.43 (8.13) | 53, 54 | <0.001 |
Current Smoker | 4,187 | <0.001 | |||||
Not-Current-Smoker | 2,115 (51%) | 1,363 (47%) | 45%, 49% | 752 (58%) | 55%, 61% | ||
Current-Smoker | 2,072 (49%) | 1,529 (53%) | 51%, 55% | 543 (42%) | 39%, 45% | ||
Cigarettes Smoked Per Day | 4,187 | 9.02 (11.88) | 9.52 (11.78) | 9.1, 10 | 7.88 (12.03) | 7.2, 8.5 | <0.001 |
Blood Pressure Medications | 4,187 | <0.001 | |||||
Not on BP Medication | 4,063 (97%) | 2,892 (100%) | 100%, 100% | 1,171 (90%) | 89%, 92% | ||
On BP Medication | 124 (3.0%) | 0 (0%) | 0.00%, 0.17% | 124 (9.6%) | 8.1%, 11% | ||
diabetes | 4,187 | <0.001 | |||||
Not Diabetic | 4,080 (97%) | 2,842 (98%) | 98%, 99% | 1,238 (96%) | 94%, 97% | ||
Diabetic | 107 (2.6%) | 50 (1.7%) | 1.3%, 2.3% | 57 (4.4%) | 3.4%, 5.7% | ||
Total Cholesterols | 4,187 | 236.65 (44.22) | 231.91 (41.88) | 230, 233 | 247.25 (47.38) | 245, 250 | <0.001 |
Systolic Blood Pressure | 4,187 | 132.29 (21.98) | 122.06 (12.97) | 122, 123 | 155.14 (20.75) | 154, 156 | <0.001 |
Diastolic Blood Pressure | 4,187 | 82.89 (11.88) | 77.99 (8.34) | 78, 78 | 93.85 (11.28) | 93, 94 | <0.001 |
BMI | 4,187 | 25.80 (4.07) | 24.98 (3.52) | 25, 25 | 27.64 (4.57) | 27, 28 | <0.001 |
Heart Rate | 4,187 | 75.88 (12.05) | 74.69 (11.53) | 74, 75 | 78.52 (12.77) | 78, 79 | <0.001 |
Glucose Level | 4,187 | 81.96 (22.90) | 80.69 (19.91) | 80, 81 | 84.78 (28.27) | 83, 86 | <0.001 |
Model | Accuracy | 95% CI | Kappa | McNemar's Test p-value | Positive Class |
|---|---|---|---|---|---|
KNN | 0.8695 | (0.8497, 0.8875) | 0.6747 | 3.58 × 10-8 | Yes |
Naïve Bayes | 0.7956 | (0.7724, 0.8174) | 0.4120 | < 2.2 × 10-16 | Yes |
SVM | 0.8813 | (0.8622, 0.8986) | 0.7153 | 0.1036 | Yes |
Model | Sensitivity | Specificity | Precision | F1_Score | Recall | NPV | PPV | Balanced Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|
K-NN | 0.9469 | 0.6925 | 0.8757 | 0.9099 | 0.9469 | 0.8508 | 0.8757 | 0.8197 | 0.6747 |
Naïve Bayes | 0.9921 | 0.3463 | 0.7763 | 0.8710 | 0.9921 | 0.9504 | 0.7763 | 0.6692 | 0.4120 |
Support Vector Machines | 0.9266 | 0.7778 | 0.9051 | 0.9157 | 0.9266 | 0.8224 | 0.9051 | 0.8522 | 0.7153 |
ML | Machine Learning |
KNN | K-Nearest Neighbors |
SVM | Support Vector Machines |
NB | Naïve Bayes |
ROC | Receiver Operating Characteristic |
AUC | Area Under the Curve |
NPV | Negative Predictive Value |
PPV | Positive Predictive Value |
F1 | F1 Score (Harmonic Mean of Precision and Recall) |
Sens | Sensitivity (True Positive Rate) |
Spec | Specificity (True Negative Rate) |
| [1] | Bekbolatova, M., Mayer, J., Ong, C. W., & Toma, M. (2024). Transformative Potential of AI in Healthcare: Definitions, Applications, and Navigating the Ethical Landscape and Public Perspectives. Healthcare, 12(2), 125-125. |
| [2] | Muriithi, D. K., Lumumba, V. W., Awe, O. O., & Muriithi, D. M. (2025). An Explainable Artificial Intelligence Models for Predicting Malaria Risk in Kenya. European Journal of Artificial Intelligence and Machine Learning, 4(1), 1-8. |
| [3] | Pugliese, R., Regondi, S., & Marini, R. (2021). Machine learning-based approach: Global trends, research directions, and regulatory standpoints. Data Science and Management, 4, 19-29. Science direct. |
| [4] | Yazici, İ., Shayea, I., & Din, J. (2023). A survey of applications of artificial intelligence and machine learning in future mobile networks-enabled systems. Engineering Science and Technology, an International Journal, 44, 101455. |
| [5] | Alnuaimi, A. F. A. H., & Albaldawi, T. H. K. (2024). An overview of machine learning classification techniques. Bio Web of Conferences/BIO Web of Conferences, 97(4), 00133-00133. |
| [6] | Han, X., Zhang, Z., Ding, N., Gu, Y., Liu, X., Huo, Y., Qiu, J., Zhang, L., Han, W., Huang, M., Jin, Q., Lan, Y., Liu, Y., Liu, Z., Lu, Z., Qiu, X., Song, R., Tang, J., Wen, J.-R., & Yuan, J. (2021). Pre-Trained Models: Past, Present and Future. AI Open, 2. |
| [7] | Oparil, S., Acelajado, M. C., Bakris, G. L., Berlowitz, D. R., Cífková, R., Dominiczak, A. F., Grassi, G., Jordan, J., Poulter, N. R., Rodgers, A., & Whelton, P. K. (2019). Hypertension. Nature Reviews Disease Primers, 4(4), 1-48. |
| [8] | Charchar, F. J., Prestes, P. R., Mills, C., Ching, S. M., Neupane, D., Marques, F. Z., Sharman, J. E., Vogt, L., Burrell, L. M., Korostovtseva, L., Zec, M., Patil, M., Schultz, M. G., Wallen, M. P., Renna, N. F., Islam, S. M. S., Hiremath, S., Gyeltshen, T., Chia, Y.-C., & Gupta, A. (2023). Lifestyle management of hypertension: International Society of Hypertension position paper endorsed by the World Hypertension League and European Society of Hypertension. Journal of Hypertension, 42(1), 23-49. |
| [9] | Iqbal, A. M., & Jamal, S. F. (2023, July 20). Essential Hypertension. Nih.gov; StatPearls Publishing. |
| [10] | Islam, M. N., Alam, Md. J., Maniruzzaman, Md., Ahmed, N. A. M. F., Ali, M., Md. Jahanur Rahman, & Dulal Chandra Roy. (2023). Predicting the risk of hypertension using machine learning algorithms: A cross sectional study in Ethiopia. PLOS ONE, 18(8), e0289613-e0289613. |
| [11] | Patel, R. (2021). Predictive analytics in business analytics: Decision tree. Advances in Decision Sciences, 26(1), 1-30. |
| [12] | Lee, H. (2022). Gradient boosting for hypertension prediction: SHAP-based interpretability analysis. BMC Medical Informatics and Decision Making, 22(1). |
| [13] | Montagna, S., Pengo, M. F., Ferretti, S., Borghi, C., Ferri, C., Grassi, G., Muiesan, M. L., & Parati, G. (2022). Machine Learning in Hypertension Detection: A Study on World Hypertension Day Data. Journal of Medical Systems, 47(1). |
| [14] | Shi, Y., Yang, K., Yang, Z., & Zhou, Y. (2021). Primer on artificial intelligence. Elsevier EBooks, 7-36. |
| [15] | Sanchez, T. R., Inostroza-Nieves, Y., Hemal, K., & Chen, W. (2023). Cross-sectional study. Translational Surgery, 219-222. |
| [16] | Sileyew, K. J. (2019). Research Design and Methodology. Text Mining - Analysis, Programming and Application, 7(1), 1-12. Intechopen. |
| [17] | Xiong, L. & Yao, Y. (2021). Study on an adaptive thermal comfort model with K-nearest-neighbors (Knn) algorithm. Building and Environment, 202, 108026. |
| [18] | Ebid, A. E., Deifalla, A. F., & Onyelowe, K. C. (2024). Data Utilization and Partitioning for Machine Learning Applications in Civil Engineering. Sustainable Civil Infrastructures, 87-100. |
| [19] | Mienye, I. D., & Jere, N. (2024). A Survey of Decision Trees: Concepts, Algorithms, and Applications. IEEE Access, 4, 1-1. |
| [20] | Muriithi, D., Lumumba, V., & Okongo, M. (2024). A Machine Learning-Based Prediction of Malaria Occurrence in Kenya. American Journal of Theoretical and Applied Statistics, 13(4), 65-72. |
| [21] | Guy, R. T., Santago, P., & Langefeld, C. D. (2012). Bootstrap aggregating of alternating decision trees to detect sets of SNPs that associate with disease. Genetic Epidemiology, 36(2), 99-106. |
| [22] | Parimbelli, E., Buonocore, T. M., Nicora, G., Michalowski, W., Wilk, S., & Bellazzi, R. (2023). Why did AI get this one wrong? — Tree-based explanations of machine learning model predictions. Artificial Intelligence in Medicine, 135, 102471. |
| [23] | Castillo-Botón, C., Casillas-Pérez, D., Casanova-Mateo, C., Ghimire, S., Cerro-Prada, E., Gutierrez, P. A., Deo, R. C., & Salcedo-Sanz, S. (2022). Machine learning regression and classification methods for fog events prediction. Atmospheric Research, 272, 106157. |
| [24] | Halder, R. K., Uddin, M. N., Uddin, Md. A., Aryal, S., & Khraisat, A. (2024). Enhancing K-nearest neighbor algorithm: a comprehensive review and performance analysis of modifications. Journal of Big Data, 11(1). |
| [25] | Lumumba, V., Kiprotich, D., Mpaine, M., Makena, N., & Kavita, M. (2024). Comparative Analysis of Cross-Validation Techniques: LOOCV, K-folds Cross-Validation, and Repeated K-folds Cross-Validation in Machine Learning Models. American Journal of Theoretical and Applied Statistics, 13(5), 127-137. |
| [26] | Lumumba, V. W., Wanjuki, T. M., & Njoroge, E. W. (2025). Evaluating the Performance of Ensemble and Single Classifiers with Explainable Artificial Intelligence (XAI) on Hypertension Risk Prediction. Computational Intelligence and Machine Learning, 6(1). |
| [27] | Sakai, T. (2025). The probability smoothing problem: Characterizations of the laplace method. Mathematical Social Sciences, 102409-102409. |
| [28] | Li, H., Jiang, L., Ganaa, E. D., Li, P., & Shen, X.-J. (2025). Robust feature enhanced deep kernel support vector machine via low rank representation and clustering. Expert Systems with Applications, 271, 126612. |
| [29] | Muriithi, D, K., L. (2021). A machine learning approach for the prediction of surgical outcomes. American Journal of Theoretical and Applied Statistics, 9(5), 57-64. |
| [30] | Witten, I. H., Frank, E., Hall, M. A., & Pal, C. J. (2016). Extending instance-based and linear models. Elsevier EBooks, 243-284. |
| [31] | Berggren, M., Kaati, L., Pelzer, B., Stiff, H., Lundmark, L., & Akrami, N. (2024). The generalizability of machine learning models of personality across two text domains. Personality and Individual Differences, 217, 112465. |
| [32] | Zhang, M. (2021). Predicting hypertension using logistic regression and SHAP values: A clinical and lifestyle factor analysis. Journal of Medical Informatics, 45(3), 123-134. |
| [33] | Ilemobayo, J. A., Durodola, O., Alade, O., Awotunde, O. J., Olanrewaju, A. T., Falana, O., Ogungbire, A., Osinuga, A., Ogunbiyi, D., Ifeanyi, A., Odezuligbo, I. E., & Edu, O. E. (2024). Hyperparameter Tuning in Machine Learning: A Comprehensive Review. Journal of Engineering Research and Reports, 26(6), 388-395. |
| [34] | Qiu, J. (2024). An Analysis of Model Evaluation with Cross-Validation: Techniques, Applications, and Recent Advances. Advances in Economics Management and Political Sciences, 99(1), 69-72. |
| [35] | Santos, M. S., Soares, J. P., Abreu, P. H., Araujo, H., & Santos, J. (2018). Cross-Validation for Imbalanced Datasets: Avoiding Overoptimistic and Overfitting Approaches [Research Frontier]. IEEE Computational Intelligence Magazine, 13(4), 59-76. |
APA Style
Waburi, E. W., Muriithi, D. K., Sundays, E. M. (2025). Integrating Explainable Machine Learning Models for Early Detection of Hypertension: A Transparent Approach to AI-Driven Healthcare. American Journal of Artificial Intelligence, 9(2), 154-166. https://doi.org/10.11648/j.ajai.20250902.17
ACS Style
Waburi, E. W.; Muriithi, D. K.; Sundays, E. M. Integrating Explainable Machine Learning Models for Early Detection of Hypertension: A Transparent Approach to AI-Driven Healthcare. Am. J. Artif. Intell. 2025, 9(2), 154-166. doi: 10.11648/j.ajai.20250902.17
@article{10.11648/j.ajai.20250902.17,
author = {Elizabeth Wahito Waburi and Dennis Kariuki Muriithi and Eugine Mukhwana Sundays},
title = {Integrating Explainable Machine Learning Models for Early Detection of Hypertension: A Transparent Approach to AI-Driven Healthcare
},
journal = {American Journal of Artificial Intelligence},
volume = {9},
number = {2},
pages = {154-166},
doi = {10.11648/j.ajai.20250902.17},
url = {https://doi.org/10.11648/j.ajai.20250902.17},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajai.20250902.17},
abstract = {Hypertension is a major public health challenge globally, often undiagnosed until severe complications arise, highlighting the critical need for early and accurate risk prediction methods. Despite advances in machine learning (ML), many models remain black boxes, limiting clinical trust and adoption. This study addresses these gaps by evaluating and interpreting three ML classifiers—Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Naïve Bayes—for hypertension risk prediction, emphasizing both predictive performance and explainability. Using a comprehensive dataset of 4,187 participants, demographic and clinical factors, including age, gender, smoking status, blood pressure, BMI, glucose levels, and medication use, were analyzed. Descriptive statistics revealed significant differences between the at-risk and no-risk groups, particularly in terms of age, blood pressure, cholesterol levels, and diabetes prevalence. Chi-square and Welch's t-tests confirmed these distinctions (p <.001), underscoring the validity of the models' inputs. Model evaluation showed SVM as the most balanced classifier with an accuracy of 88.13% (95% CI [86.22%, 89.86%]) and substantial agreement (kappa = 0.7153). It achieved strong sensitivity (92.66%) and specificity (77.78%), alongside a favorable F1-score (0.9157), indicating robust true positive detection while minimizing false positives. KNN demonstrated high sensitivity (94.69%) but lower specificity (69.25%), with moderate overall accuracy (86.95%). Naïve Bayes, though highly sensitive (99.21%), suffered from poor specificity (34.63%), suggesting a high false-positive rate and imbalanced classification. McNemar's test indicated balanced errors only for SVM (p = 0.1036). Receiver Operating Characteristic (ROC) analysis revealed excellent discrimination for all models, with Naïve Bayes achieving an AUC of 0.953; however, this did not translate into practical reliability due to error imbalance. Explainable AI techniques, specifically SHAP values, elucidated key predictors in SVM, notably systolic and diastolic blood pressure, BMI, and heart rate, enhancing interpretability and stakeholder trust. According to the study, SVM offers the best trade-off between accuracy and interpretability for predicting hypertension risk. Integrating explainable ML models into clinical practice can improve early diagnosis, guide interventions, and inform health policies, supporting ethical, transparent, and effective AI-driven healthcare.
},
year = {2025}
}
TY - JOUR T1 - Integrating Explainable Machine Learning Models for Early Detection of Hypertension: A Transparent Approach to AI-Driven Healthcare AU - Elizabeth Wahito Waburi AU - Dennis Kariuki Muriithi AU - Eugine Mukhwana Sundays Y1 - 2025/09/23 PY - 2025 N1 - https://doi.org/10.11648/j.ajai.20250902.17 DO - 10.11648/j.ajai.20250902.17 T2 - American Journal of Artificial Intelligence JF - American Journal of Artificial Intelligence JO - American Journal of Artificial Intelligence SP - 154 EP - 166 PB - Science Publishing Group SN - 2639-9733 UR - https://doi.org/10.11648/j.ajai.20250902.17 AB - Hypertension is a major public health challenge globally, often undiagnosed until severe complications arise, highlighting the critical need for early and accurate risk prediction methods. Despite advances in machine learning (ML), many models remain black boxes, limiting clinical trust and adoption. This study addresses these gaps by evaluating and interpreting three ML classifiers—Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Naïve Bayes—for hypertension risk prediction, emphasizing both predictive performance and explainability. Using a comprehensive dataset of 4,187 participants, demographic and clinical factors, including age, gender, smoking status, blood pressure, BMI, glucose levels, and medication use, were analyzed. Descriptive statistics revealed significant differences between the at-risk and no-risk groups, particularly in terms of age, blood pressure, cholesterol levels, and diabetes prevalence. Chi-square and Welch's t-tests confirmed these distinctions (p <.001), underscoring the validity of the models' inputs. Model evaluation showed SVM as the most balanced classifier with an accuracy of 88.13% (95% CI [86.22%, 89.86%]) and substantial agreement (kappa = 0.7153). It achieved strong sensitivity (92.66%) and specificity (77.78%), alongside a favorable F1-score (0.9157), indicating robust true positive detection while minimizing false positives. KNN demonstrated high sensitivity (94.69%) but lower specificity (69.25%), with moderate overall accuracy (86.95%). Naïve Bayes, though highly sensitive (99.21%), suffered from poor specificity (34.63%), suggesting a high false-positive rate and imbalanced classification. McNemar's test indicated balanced errors only for SVM (p = 0.1036). Receiver Operating Characteristic (ROC) analysis revealed excellent discrimination for all models, with Naïve Bayes achieving an AUC of 0.953; however, this did not translate into practical reliability due to error imbalance. Explainable AI techniques, specifically SHAP values, elucidated key predictors in SVM, notably systolic and diastolic blood pressure, BMI, and heart rate, enhancing interpretability and stakeholder trust. According to the study, SVM offers the best trade-off between accuracy and interpretability for predicting hypertension risk. Integrating explainable ML models into clinical practice can improve early diagnosis, guide interventions, and inform health policies, supporting ethical, transparent, and effective AI-driven healthcare. VL - 9 IS - 2 ER -
Department of Physical Sciences, Chuka University, Chuka, Kenya
Department of Physical Sciences, Chuka University, Chuka, Kenya
Department of Nursing, Chuka University, Chuka, Kenya
Information