Deep Learning (DL) models for survival analysis have been employed to predict different long-term illnesses, such as diabetes, in the healthcare system. In these medical datasets, numerous features about a patient are recorded, which may limit the performance of these deep-learning models. The regularization approach is considered as a strategy to reduce network weights hence deep learning architectures have been proposed to handle the weights of the features in the soft feature selection technique. Deep networks such as Deephit have been employed in survival analysis to handle competing risks. In addition, the model can learn the survival distribution directly, however, the model’s accuracy cannot be guaranteed when we have many irrelevant features recorded about a given patient. This research proposes to develop a novel model by exploiting the sparsity regulation technique on the fully connected layers. To achieve this, we modified DeepHit’s architecture by adding a sparsity layer for the feature selection. Specifically, the Combined Group and Exclusive Sparsity Regularization were used for feature selection by exploiting sharing and competing relationships among network weights. The researcher trained the model using a diabetic dataset obtained from the Kaggle data repository and compared the efficacy of different models. The findings from the study revealed that the DeepHit-Combined Group Exclusive Sparsity (CGES) model achieved a more efficient network while at the same time improving its performance compared to other base networks with full weights. This research contributes valuable insights for regulators and medical practitioners in giving essential standards of care to diabetic patients to reduce complications, diabetic-related illnesses, and associated costs.
| Published in | American Journal of Applied Mathematics (Volume 13, Issue 2) |
| DOI | 10.11648/j.ajam.20251302.16 |
| Page(s) | 165-173 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Artificial Neural Network (ANN), Combined Group and Exclusive Sparsity (CGES), Competing Risks (CR), Cumulative Incidence Function (CIF), Deep Learning (DL)
No. | Explanatory Variables | No. | Explanatory Variables |
|---|---|---|---|
1 | Age of Patients | 11 | Types of Diabetes |
2 | Blood Glucose Level | 12 | Cholesterol Level |
3 | Sex | 13 | Marital Status |
4 | Past Family History | 14 | Employment |
5 | Regimen | 15 | Smoking |
6 | Blood Pressure | 16 | Any Healthcare Coverage |
7 | Physical Activity | 17 | General Health |
8 | Income | 18 | Level of education |
9 | Mental Health | 19 | Physical health |
10 | Body Mass Index (BMI) | ||
Rank | Causes of Death | |||||
|---|---|---|---|---|---|---|
Diabetes | Stroke | Heart Disease | ||||
Feature | Importance (WAV) | Feature | Importance (WAV) | Feature | Importance (WAV) | |
1 | Age | 0.151461 | Age | 0.215366 | Age | 0.244801 |
2 | BMI | 0.140506 | Sex | 0.147312 | Diabetes Type | 0.167733 |
3 | Sex | 0.127359 | BMI | 0.091544 | Sex | 0.068167 |
4 | Diabetes Type | 0.097647 | Family History | 0.077154 | BMI | 0.058409 |
5 | Family History | 0.075131 | Smoker | 0.064789 | Family History | 0.054690 |
6 | Blood Glucose | 0.062676 | Blood Pressure | 0.042899 | Blood Pressure | 0.037006 |
7 | Blood Pressure | 0.053332 | General Health | 0.032045 | Smoker | 0.032934 |
8 | Education | 0.046267 | Diabetes Type | 0.020033 | Education | 0.027868 |
9 | Income | 0.028818 | Marital Status | 0.019821 | General Health | 0.021602 |
10 | General Health | 0.017610 | Education | 0.014161 | Income | 0.018450 |
Event/Model | Diabetes | Stroke | Heart Disease | |||
|---|---|---|---|---|---|---|
Mean | SD | Mean | SD | Mean | SD | |
Sparse-DeepHit | 0.760 | 0.027 | 0.773 | 0.012 | 0.780 | 0.011 |
Dynamic-DeepHit | 0.740 | 0.031 | 0.765 | 0.014 | 0.779 | 0.013 |
DeepHit | 0.684 | 0.038 | 0.691 | 0.026 | 0.752 | 0.020 |
Proposed Model | 0.770 | 0.022 | 0.790 | 0.010 | 0.799 | 0.088 |
Event/Model | Diabetes | Stroke | Heart Disease |
|---|---|---|---|
MSE | MSE | MSE | |
Sparse-DeepHit | 0.071 | 0.065 | 0.063 |
Dynamic-DeepHit | 0.074 | 0.069 | 0.066 |
DeepHit | 0.078 | 0.076 | 0.075 |
Proposed Model | 0.068 | 0.064 | 0.059 |
AI | Artificial Intelligence |
ANN | Artificial Neural Network |
CDC | Center for Disease Control and Prevention |
CGES | Combined Group and Exclusive Sparsity |
CIF | Cumulative Incidence Function |
CR | Competing Risks |
DL | Deep Learning |
| [1] | Alvarez, J. M., & Salzmann, M. (2016). Learning the number of neurons in deep networks. Advances in neural information processing systems, 29. |
| [2] | American Diabetes Association. (2021). Classification and diagnosis of diabetes: standards of medical care in diabetes—2021. Diabetes care, 44 (Supplement_1), S15-S33. |
| [3] | Atlas, D. (2021). International diabetes federation. IDF Diabetes Atlas, 10th ed. Brussels, Belgium: International Diabetes Federation, 33(2). |
| [4] | Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, 160-167. |
| [5] | Federation ID. (2021) Diabetes atlas. 10th Edition. Brussels, Belgium. |
| [6] | Fine, J. P., & Gray, R. J. (1999). A Proportional Hazards model for the sub-distribution of a competing risk. Journal of the American Statistical Association, 94(446), 496–509. |
| [7] | Kim, S., & Xing, E. P. (2010). Tree-guided group lasso for multi-task regression with structured sparsity ICML. Google Scholar Google Scholar Digital Library Digital Library, 6(3), 1095-1117. |
| [8] | Lee, C., Yoon, J., & Van Der Schaar, M. (2019). Dynamic-Deephit: A deep learning approach for dynamic survival analysis with competing risks based on longitudinal data. IEEE Transactions on Biomedical Engineering, 67(1), 122-133. |
| [9] | Lee, C., Zame, W., Yoon, J., & Van Der Schaar, M. (2018, April). Deephit: A deep learning approach to survival analysis with competing risks. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1). |
| [10] | Ormazabal, V. et al. (2018). Association between insulin resistance and the development of cardiovascular disease. Cardiovascular Diabetology, 17, 122. |
| [11] | Rietschel, C. (2018). Automated feature selection for survival analysis with deep learning (Doctoral dissertation, University of Oxford). |
| [12] | Schoop, R., Beyersmann, J., Schumacher, M., & Binder, H. (2011). Quantifying the predictive accuracy of time‐to‐event models in the presence of competing risks. Biometrical Journal, 53(1), 88-112. |
| [13] | Wen, W., Wu, C., Wang, Y., Chen, Y., & Li, H. (2016). Learning structured sparsity in deep neural networks. Advances in neural information processing systems, 29. |
| [14] | World Health Organization. (2021). Diabetes Fact Sheet. |
| [15] | Yoon, J., & Hwang, S. J. (2017). Combined Group and Exclusive Sparsity for Deep Neural Networks. International Conference on Machine Learning, 7, 81-89. |
| [16] | Yu, C-N., Greiner, R., Lin, H-C., & Baracos, V. (2011). Learning patient-specific cancer survival distributions as a sequence of dependent regressors. In Advances in Neural Information Processing Systems 24. |
| [17] | Zhou, Y., Jin, R., & Hoi, S. C. H. (2010, March). Exclusive lasso for multi-task feature selection. In Proceedings of the thirteenth international conference on artificial intelligence and statistics (pp. 988-995). JMLR Workshop and Conference Proceedings. |
APA Style
David, J. R., Imboga, H., Mwelu, S. (2025). Survival Analysis of Diabetic Patients Using Deephit with a Modified Sparsity Layer. American Journal of Applied Mathematics, 13(2), 165-173. https://doi.org/10.11648/j.ajam.20251302.16
ACS Style
David, J. R.; Imboga, H.; Mwelu, S. Survival Analysis of Diabetic Patients Using Deephit with a Modified Sparsity Layer. Am. J. Appl. Math. 2025, 13(2), 165-173. doi: 10.11648/j.ajam.20251302.16
AMA Style
David JR, Imboga H, Mwelu S. Survival Analysis of Diabetic Patients Using Deephit with a Modified Sparsity Layer. Am J Appl Math. 2025;13(2):165-173. doi: 10.11648/j.ajam.20251302.16
@article{10.11648/j.ajam.20251302.16,
author = {James Rioba David and Herbert Imboga and Susan Mwelu},
title = {Survival Analysis of Diabetic Patients Using Deephit with a Modified Sparsity Layer
},
journal = {American Journal of Applied Mathematics},
volume = {13},
number = {2},
pages = {165-173},
doi = {10.11648/j.ajam.20251302.16},
url = {https://doi.org/10.11648/j.ajam.20251302.16},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajam.20251302.16},
abstract = {Deep Learning (DL) models for survival analysis have been employed to predict different long-term illnesses, such as diabetes, in the healthcare system. In these medical datasets, numerous features about a patient are recorded, which may limit the performance of these deep-learning models. The regularization approach is considered as a strategy to reduce network weights hence deep learning architectures have been proposed to handle the weights of the features in the soft feature selection technique. Deep networks such as Deephit have been employed in survival analysis to handle competing risks. In addition, the model can learn the survival distribution directly, however, the model’s accuracy cannot be guaranteed when we have many irrelevant features recorded about a given patient. This research proposes to develop a novel model by exploiting the sparsity regulation technique on the fully connected layers. To achieve this, we modified DeepHit’s architecture by adding a sparsity layer for the feature selection. Specifically, the Combined Group and Exclusive Sparsity Regularization were used for feature selection by exploiting sharing and competing relationships among network weights. The researcher trained the model using a diabetic dataset obtained from the Kaggle data repository and compared the efficacy of different models. The findings from the study revealed that the DeepHit-Combined Group Exclusive Sparsity (CGES) model achieved a more efficient network while at the same time improving its performance compared to other base networks with full weights. This research contributes valuable insights for regulators and medical practitioners in giving essential standards of care to diabetic patients to reduce complications, diabetic-related illnesses, and associated costs.
},
year = {2025}
}
TY - JOUR T1 - Survival Analysis of Diabetic Patients Using Deephit with a Modified Sparsity Layer AU - James Rioba David AU - Herbert Imboga AU - Susan Mwelu Y1 - 2025/03/31 PY - 2025 N1 - https://doi.org/10.11648/j.ajam.20251302.16 DO - 10.11648/j.ajam.20251302.16 T2 - American Journal of Applied Mathematics JF - American Journal of Applied Mathematics JO - American Journal of Applied Mathematics SP - 165 EP - 173 PB - Science Publishing Group SN - 2330-006X UR - https://doi.org/10.11648/j.ajam.20251302.16 AB - Deep Learning (DL) models for survival analysis have been employed to predict different long-term illnesses, such as diabetes, in the healthcare system. In these medical datasets, numerous features about a patient are recorded, which may limit the performance of these deep-learning models. The regularization approach is considered as a strategy to reduce network weights hence deep learning architectures have been proposed to handle the weights of the features in the soft feature selection technique. Deep networks such as Deephit have been employed in survival analysis to handle competing risks. In addition, the model can learn the survival distribution directly, however, the model’s accuracy cannot be guaranteed when we have many irrelevant features recorded about a given patient. This research proposes to develop a novel model by exploiting the sparsity regulation technique on the fully connected layers. To achieve this, we modified DeepHit’s architecture by adding a sparsity layer for the feature selection. Specifically, the Combined Group and Exclusive Sparsity Regularization were used for feature selection by exploiting sharing and competing relationships among network weights. The researcher trained the model using a diabetic dataset obtained from the Kaggle data repository and compared the efficacy of different models. The findings from the study revealed that the DeepHit-Combined Group Exclusive Sparsity (CGES) model achieved a more efficient network while at the same time improving its performance compared to other base networks with full weights. This research contributes valuable insights for regulators and medical practitioners in giving essential standards of care to diabetic patients to reduce complications, diabetic-related illnesses, and associated costs. VL - 13 IS - 2 ER -
Department of Statistics and Actuarial Science, Jomo Kenyatta University of Agriculture and Technology, Nairobi, Kenya
Department of Statistics and Actuarial Science, Jomo Kenyatta University of Agriculture and Technology, Nairobi, Kenya
Department of Statistics and Actuarial Science, Jomo Kenyatta University of Agriculture and Technology, Nairobi, Kenya
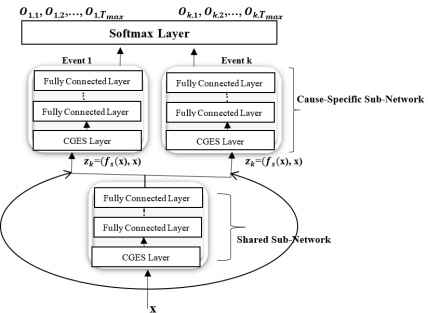
Figure 1.
Network Architecture of our Model with K Competing Risks.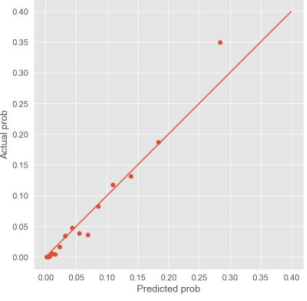
Figure 2. Calibration Plot for Our Model.
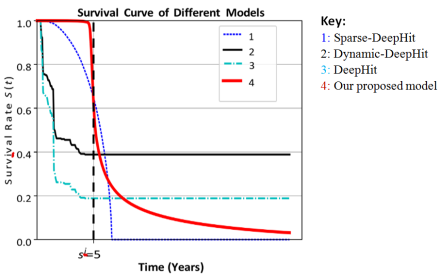
Figure 3. Survival rate S(t|) estimation over different models. The vertical dotted line is the true event time of this sample.
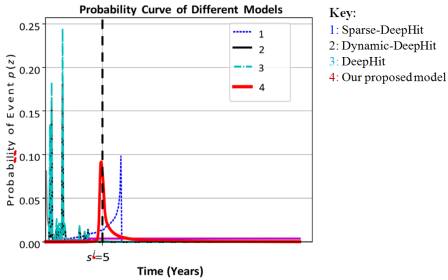
Figure 4. Event Time Probability Prediction over Different Models. The vertical dotted line is the true event time t of this sample.
Information

