Abstract
Short-term load forecasting (STLF) serves as a fundamental basis for the efficient operation of smart grids and energy management systems. Accurate nodal-level load prediction plays a vital role in optimizing power dispatching, reducing operational costs, and enhancing grid security. Variations in user behavior patterns, geographical location, and equipment characteristics among different electricity nodes typically result in load profiles that exhibit pronounced volatility and non-stationarity. Traditional single model forecasting approaches are highly sensitive to data distribution and often struggle to maintain consistently high predictive accuracy across all nodes. Specifically, individual models frequently lack the generalization capability required for diverse load types, leading to significant error variability when applied to nodes with contrasting properties. To address these limitations, this study proposes a highly robust heterogeneous ensemble learning framework. First, a forecasting repository comprising six differentiated base models is constructed to accommodate diversity in model errors. Subsequently, a stacking-based meta-learning strategy is applied to integrate the outputs of the base models, enabling the extraction of multi-dimensional temporal features. To comprehensively validate the effectiveness of the proposed method, extensive comparative experiments are conducted using datasets from ten electricity nodes with diverse distribution characteristics. Experimental results demonstrate that the ensemble model significantly outperforms the base models in terms of accuracy while exhibiting superior stability across various nodes.
Keywords
Power Load Forecasting, Ensemble Learning, Stacking, Stability Analysis, Deep Learning
1. Introduction
The electrical energy infrastructure serves as a critical foundation for contemporary economic expansion and societal stability. With the rapid advancement of smart grid technologies and the integration of distributed renewable energy sources, the operational complexity of power networks has increased substantially. Consequently, short-term load forecasting (STLF) has emerged as a vital component for intelligent grid management. Accurate prediction provides essential decision support for power dispatching, unit scheduling, and maintenance planning, thereby ensuring the security, reliability, and cost-effectiveness of the entire power system.
The reliability of electrical networks heavily depends on precise forecasting of energy consumption
| [1] | Xu, H. Y., Zhang, Y., & Zhao, Y. (2023). Short-term electricity load forecasting based on ensemble empirical mode decomposition and long short-term memory neural network. In Proceedings of the 2023 IEEE International Conference on Energy Internet (ICEI), October 20-22, Shenyang, China, pp. 271-275. https://doi.org/10.1109/ICEI60179.2023.00058 |
[1]
. However, STLF has remained a complex issue due to the unpredictable and dynamic nature of power consumption patterns. Multiple variables influence electricity demand profiles, including weather conditions (such as ambient temperature and moisture levels), temporal factors (such as public holidays and non-working days), and societal and economic behaviors. The complexity escalates when attempting to predict consumption of individual electricity nodes rather than the entire power network.
Different segments of the power grid, including industrial zones, business centers, and residential neighborhoods, exhibit distinct power usage trends and probability distributions. Goel et al.
| [2] | Goel, L., Wu, Q. W., & Wang, P. (2010). Fuzzy logic-based direct load control of air conditioning loads considering nodal reliability characteristics in restructured power systems. Electric Power Systems Research, 80(1), 98-107.
https://doi.org/10.1016/j.epsr.2009.08.009 |
[2]
highlighted that loads connected to various nodes possess differing characteristics, which significantly impacts demand management strategies. For instance, industrial nodes experience sudden spikes in demand aligned with factory operations, while residential nodes show more consistent usage patterns influenced by daily routines. This inherent diversity implies that predictive algorithms tailored for specific data categories often fail to maintain consistent performance across heterogeneous nodes, resulting in suboptimal network-wide accuracy. Historically, methodologies for addressing STLF challenges have predominantly fallen into two categories: those grounded in statistical analysis and those utilizing machine learning techniques. Traditional statistical approaches, as discussed by Bunn
, focused on capturing linear dependencies within sequential data. However, these methods are typically constrained by their linear assumptions, making them less effective in modeling the complex, non-linear interactions prevalent in contemporary electricity demand patterns.
To address the limitations of traditional statistical methods, machine learning techniques have gained widespread adoption. These approaches demonstrate exceptional capability in processing complex nonlinear relationships and extracting patterns from high-dimensional datasets. As noted by Aguilar Madrid and Antonio
, these methods outperform conventional models by effectively incorporating additional relevant variables. Furthermore, modern architecture autonomously discovers intricate data representations, removing the necessity for manual feature extraction
| [5] | Lim, B., & Zohren, S. (2021). Time-series forecasting with deep learning: A survey. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 379(2194), 20200209.
https://doi.org/10.1098/rsta.2020.0209 |
[5]
.
However, both conventional machine learning and advanced deep learning methods inevitably share certain limitations. Theoretical principles suggest that no universal algorithm can optimally address every data distribution, meaning singular models often struggle to adapt to nodes with erratic consumption behaviors. Furthermore, individual models frequently suffer from overfitting and high sensitivity, where minor input variations lead to divergent forecasts
. Such inconsistencies pose operational risks, as a model optimized for one specific node often lacks the generalization capability required for reliable system-level deployment. Recognizing these limitations, this study proposes a heterogeneous ensemble learning framework designed to enhance both accuracy and stability across diverse nodes. Unlike homogeneous ensembles, our approach integrates six distinct algorithms: logistic regression (LR), decision tree (DT), random forest (RF), multilayer perceptron (MLP), convolutional neural network (CNN), and long short-term memory (LSTM). This combination spans paradigms from linear modeling to deep learning, promoting varied error patterns. This approach leverages model diversity to reduce error correlation while dynamically optimizing weights to enhance robustness against individual model failures
| [7] | Krogh, A., & Vedelsby, J. (1994). Neural network ensembles, cross validation, and active learning. In Proceedings of the 7th International Conference on Neural Information Processing Systems (NIPS), November 28-December 1, Denver, USA, pp. 231-238. |
[7]
. Validated across ten distinct electricity distribution nodes, the proposed stacking-based ensemble model (SBEM) consistently outperforms base models in both accuracy and stability, offering a reliable solution for smart grid scheduling under varying data distributions.
The structure of this paper is organized as follows: section 2 reviews existing literature on forecasting methodologies, encompassing both statistical and machine learning techniques. Section 3 provides a detailed explanation of our methodology, covering data preparation procedures, base model development, and ensemble learning approaches. Experimental evaluations and comparative analyses are presented in section 4, followed by concluding remarks in section 5.
2. Related Work
STLF has been extensively researched, with methodological evolution progressing from conventional statistical approaches to contemporary machine learning solutions. This section systematically categorizes current research into statistics-based methods and machine learning-based methods, while highlighting limitations in prior studies that motivate our comprehensive ensemble modeling approach.
2.1. Statistics-Based Methods
Statistical approaches rely on mathematical frameworks to analyze historical time series, identifying recurring patterns and linear dependencies within the data. Among the various methodologies in this category, the autoregressive integrated moving average (ARIMA) framework stands out as one of the most frequently employed techniques. As systematically defined in classic forecasting literature, this model has demonstrated exceptional capability in capturing linear patterns within time series data that exhibit stationarity
| [8] | Makridakis, S., Wheelwright, S. C., & Hyndman, R. J. (1998). Forecasting: Methods and Applications (3rd ed.). John Wiley & Sons. |
[8]
. Zhang
employed the ARIMA framework to model the linear components of historical power load data, verifying its robustness in tracking regular trend variations. Modified versions of the standard ARIMA approach, incorporating techniques such as wavelet transforms or seasonal time series decomposition, have also been suggested as effective for analyzing the periodic fluctuations in power consumption. However, rigorous evaluations highlight that the predictive accuracy of these statistical methods significantly diminishes when applied to datasets exhibiting abrupt fluctuations or non-stationary characteristic
. Neither basic linear models nor their seasonally adjusted variants can adequately address the complex non-linear volatilities inherent in power systems.
Another widely employed statistical method is known as exponential smoothing (ES). In contrast to ARIMA models that focus solely on autocorrelations, ES applies progressively diminishing weights to historical data points, thereby increasing sensitivity to recent trend variations. This approach has spawned specialized variants like Holt-Winters smoothing, which effectively identifies seasonal patterns. Almazrouee et al.
| [11] | Almazrouee, A. I., Almeshal, A. M., Almutairi, A. S., Alenezi, M. R., & Alhajeri, S. N. (2020). Long-term forecasting of electrical loads in Kuwait using Prophet and Holt-Winters models. Applied Sciences, 10(16), 5627.
https://doi.org/10.3390/app10165627 |
[11]
demonstrated this through their development of various Holt-Winters models, significantly improving ultra-short-term electricity demand predictions for Spain's power grid.
Similarly, multiple linear regression (MLR) techniques have proven valuable for quantifying relationships between power consumption and external variables including weather conditions and economic metrics. By utilizing least squares optimization of parameters, MLR enables precise measurement of how different variables influence electricity usage patterns. Statistical analysis examines how specific variables influence others under predetermined conditions
. Building on this, Fumo and Biswa
highlighted the effectiveness of regression analysis in identifying stable linear correlations between energy usage patterns and weather conditions across different residential types. However, since electricity consumption patterns result from complex nonlinear human behaviors and unpredictable weather phenomena, conventional statistical techniques often fail to account for rapid fluctuations and sophisticated interrelationships. Consequently, such models struggle to represent the nonlinear characteristics and dynamic complexities inherent in power systems, resulting in diminished prediction precision
| [14] | Akhtar, S., Shahzad, S., Zaheer, A., Ullah, H. S., Kilic, H., Gono, R., Jasiński, M., & Leonowicz, Z. (2023). Short-term load forecasting models: A review of challenges, progress, and the road ahead. Energies, 16(10), 4060.
https://doi.org/10.3390/en16104060 |
[14]
.
2.2. Machine Learning-Based Methods
Artificial intelligence techniques, particularly those utilizing machine learning algorithms, have become the predominant methodology in STLF. These advanced computational methods effectively address the limitations of traditional statistical approaches when handling complex, non-linear data patterns. By leveraging large-scale historical datasets, machine learning systems autonomously identify hidden structural relationships without requiring predefined assumptions, demonstrating superior adaptability and performance in modeling intricate electrical load behaviors.
Early applications of machine learning in STLF focused on foundational models such as LR, MLP and support vector machine (SVM). While LR serves as a computational baseline for identifying linear trends, MLP utilizes a multi-layered feedforward structure that demonstrates a superior ability to map the complex, non-linear interactions between load demand and meteorological variables
| [15] | Baliyan, A., Gaurav, K., & Mishra, S. K. (2015). A review of short term load forecasting using artificial neural network models. Procedia Computer Science, 48, 121-125.
https://doi.org/10.1016/j.procs.2015.04.160 |
[15]
. Furthermore, SVM has proven effective in scenarios with limited sample sizes or significant noise. By optimizing penalty parameters, recent studies have shown that SVM-based approaches can significantly boost forecasting precision in localized grid environments
| [16] | Zhou, Y., Liu, T. Y., & Yang, E. K. (2024). Machine learning model based on improved DBO algorithm optimized SVM. In Proceedings of the 2024 6th International Conference on Natural Language Processing (ICNLP), March 22-24, Xi'an, China, pp. 162-168.
https://doi.org/10.1109/ICNLP60986.2024.10692711 |
[16]
. To further enhance generalization, ensemble strategies like RF have been widely implemented. By synthesizing the outputs of numerous independent DT, RF effectively mitigates the risk of overfitting inherent in single estimators. Recent research indicates that this aggregation technique is particularly robust when processing high-dimensional datasets containing complex meteorological and calendar variables, resulting in enhanced predictive stability and accuracy
| [17] | Magalhães, B., Bento, P., Pombo, J., Calado, M. R., & Mariano, S. (2024). Short-term load forecasting based on optimized random forest and optimal feature selection. Energies, 17(8), 1926. https://doi.org/10.3390/en17081926 |
[17]
.
In recent years, deep learning has gained widespread adoption. CNN has been adapted from vision tasks to time-series analysis and utilized primarily to extract latent local features and invariant structures from volatile load curves. Meanwhile, LSTM networks have emerged as the standard for sequential modeling. In the context of STLF, LSTM has been specifically employed to capture long-range temporal dependencies in electricity consumption data, effectively utilizing historical patterns to predict future demand
| [18] | Amalou, I., Mouhni, N., & Abdali, A. (2024). CNN-LSTM architectures for non-stationary time series: Decomposition approach. In Proceedings of the 2024 International Conference on Global Aeronautical Engineering and Satellite Technology (GAST), April 24-26, Marrakesh, Morocco, pp. 1-5.
https://doi.org/10.1109/GAST60528.2024.10520774 |
[18]
. The integration of CNN and LSTM has further enhanced predictive performance by simultaneously extracting spatial and temporal features. Research has demonstrated that this architectural design excels in predicting time series data due to its comprehensive integration of essential elements needed to represent intricate patterns. Unlike alternative structural approaches, it effectively captures the multifaceted nature of temporal sequences that other models fail to adequately address and have been well used for big data analysis of electricity
| [19] | Yoon, N., Lee, S., Kim, S. K., Park, C., Kim, T., & Jin, H. (2024). Energy consumption prediction using CNN-LSTM models: A time series big data analysis of electricity, heating, hot water, and water. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), November 3-6, Da Nang, Vietnam, pp. 1-4.
https://doi.org/10.1109/ICCE-Asia63397.2024.10774020 |
[19]
.
Despite these advancements, a critical limitation remains unresolved: the stability of individual models. While LSTM or CNN architecture perform well on specific datasets, they often struggle to adapt to data with contrasting statistical properties, such as different load types. Individual models tend to converge on suboptimal local solutions and exhibit significant variability in error distribution. Increasing the number of hidden layers enhances a model's expressive power, but this often comes at the cost of worsening overfitting tendencies
| [19] | Yoon, N., Lee, S., Kim, S. K., Park, C., Kim, T., & Jin, H. (2024). Energy consumption prediction using CNN-LSTM models: A time series big data analysis of electricity, heating, hot water, and water. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), November 3-6, Da Nang, Vietnam, pp. 1-4.
https://doi.org/10.1109/ICCE-Asia63397.2024.10774020 |
[19]
. To address the limitations, this study proposes a diversified ensemble approach to integrate multiple algorithms, thereby achieving improved consistency across different data nodes.
3. Methodology
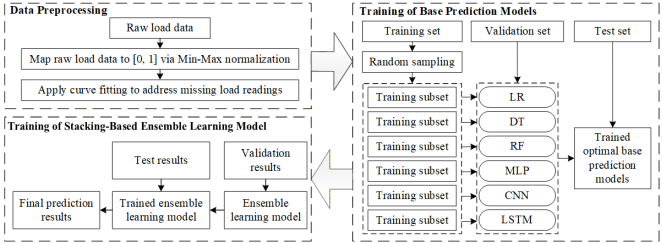
This study proposes a SBEM designed to integrate the predictive capabilities of heterogeneous algorithms. As shown in
Figure 1, the framework consists of three sequential stages: data preprocessing, training of base prediction models, and training of stacking-based ensemble learning model.
Figure 1. The structure of the SBEM. The structure of the SBEM.
3.1. Data Preprocessing
High-quality training data serves as the fundamental requirement for accurate predictive modeling. Electrical consumption records collected through smart metering systems often contain measurement artifacts, incomplete entries, and inconsistent magnitudes, which hinder model optimization. Essential preprocessing procedures involve feature scaling and missing value imputation.
First, since the base models are sensitive to the magnitude of input features, we apply min-max normalization to scale the raw load series. This transformation maps all load values into the range [0, 1], preventing variables with larger absolute values from dominating the gradient descent process during training, which is calculated as shown in Eq. (
1).
(1)
where indicates the value of the normalized data, which ranges from 0 to 1. indicates the value of the raw data. and indicates the maximum and minimum values of the raw data in the dataset, respectively.
Subsequently, to resolve disruptions in temporal continuity resulting from equipment malfunctions or data transmission anomalies, we execute missing value imputation. Gaps within the sequential measurements are detected and appropriately reconstructed to preserve the chronological coherence of the time series. Our methodology incorporates various completion techniques including null value substitution and curve fitting approaches to guarantee that the predictive models receive comprehensive and coherent data streams
| [20] | Alam, S., Dubey, A., & Bisen, D. (2025). An ensemble-based framework for enhanced missing data imputation. In Proceedings of the 2025 IEEE 14th International Conference on Communication Systems and Network Technologies (CSNT), March 7-9, Bhopal, India, pp. 647-651.
https://doi.org/10.1109/CSNT64827.2025.10967640 |
[20]
.
3.2. Training of Base Prediction Models
The core of our ensemble framework is the forecasting repository, which comprises six distinct base prediction models chosen for their diverse learning mechanisms: LR, DT, RF, MLP, CNN, and LSTM.
During this phase, the dataset is primarily partitioned into training, validation, and test sets. Subsequently, we apply random sampling to the training set to generate distinct training subsets for the independent development of multiple predictive models. Such an approach facilitates the acquisition of robust feature representations by our models. Subsequently, we perform individual optimization for every base model (utilizing the validation set to adjust specific hyperparameters like DT depth or neural network layer count). As a result, we obtain six refined base prediction models, with each producing independent forecasts. The diversity among these models, which include algorithms varying from simple linear regression to sophisticated temporal deep learning architectures, plays a vital role in the subsequent ensemble process.
3.3. Training of Stacking-Based Ensemble Learning Model
The third stage involves building the SBEM. Essentially, stacking represents a hierarchical ensemble technique where predictions from base models serve as input variables for a higher-level predictive model.
During the model selection process, the trained base models utilize the validation dataset to derive the predictor variables of the validation dataset. These predictor variables are subsequently combined to form an additional feature matrix. Thereafter, these predictor variables serve as training inputs to establish the final ensemble learning model. Upon completion of training, the test dataset is processed by the base models to obtain corresponding predictor variables. These test-based inputs are then processed by the trained ensemble model to yield the final predicted results.
4. Experiments
This section evaluates the distinction between individual base models and the SBEM through comparative experiments and error analysis, with additional comprehensive performance assessments conducted on the SBEM.
4.1. Data Description
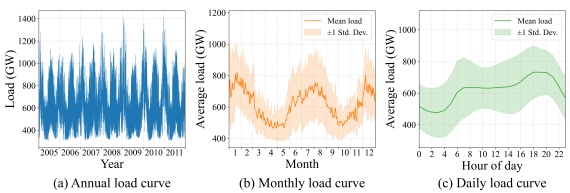
The present study employs the GEFCom2017 dataset to validate the performance of the proposed model. This dataset comprises energy consumption data from an undisclosed region in the United States, spanning the period from January 1, 2005, to December 31, 2011, and has been widely utilized in load forecasting research. To provide an intuitive representation of the dataset's content, three types of load curves, annual, monthly, and daily, for the period from January 1, 2005, to December 31, 2011, are illustrated in
Figure 2. Initially, a linear interpolation method was applied to address minor data gaps and loads from 100 independent regions were aggregated to derive the total system load. The annual load curve depicts the complete chronological load profile across the seven-year span, revealing a stable long-term electricity consumption pattern. The monthly load curve and daily load curve elucidate the seasonal and diurnal characteristics of the load, respectively. The vertical axis of the monthly load curve is defined as the "historical average load for the corresponding period", which is calculated by grouping all samples in the dataset by "day of the year" and computing the arithmetic mean of the seven-year data within each group. This reflects the fluctuation in electricity demand driven by seasonal changes. The vertical axis of the daily load curve is defined as the "time-based average load" which is derived from the average load across all samples at each corresponding hourly interval (0-23) throughout the dataset. This demonstrates the grid's characteristic dual-peak pattern of morning and evening loads.
Figure 2. Load curve of GEFCom2017 dataset.Load curve of GEFCom2017 dataset.
4.2. Experimental Settings
The research utilized Python programming language. This computing system was equipped with an intel core i7 processor operating at 5.60 GHz clock speed, coupled with an NVIDIA GeForce RTX 5070Ti graphics processing unit.
4.3. Evaluation Metrics
This study selected three evaluation metrics: mean absolute error (MAE), mean absolute percentage error (MAPE) and root mean square error (RMSE).
MAE: Eq. (
2) defines the computational procedure for evaluating the deviation between actual and predicted values.
MAPE: Eq. (
3) defines the computational procedure for determining the average proportion of the relative error existing between the actual value and the predicted value.
(3)
RMSE: Eq. (
4) defines the computational procedure for measuring the extent of deviation between the actual value and the predicted value.
(4)
where , , and represent the sample size, ground truth, and predictions of the test set, respectively. Lower values of MAE, MAPE, and RMSE indicate superior models.
4.4. Performance Comparison
To validate the performance of SBEM in power load forecasting tasks, this section conducts comparative tests with six independent base models. The experiment employs the previously mentioned three evaluation metrics to quantify the forecasting performance of each model, with detailed data from three distinctly different nodes presented in
Table 1.
As evidenced in
Table 1, SBEM consistently demonstrates superior performance across all evaluation criteria when compared with individual base models. These results clearly highlight SBEM's enhanced predictive accuracy and its comprehensive advantages for electrical load forecasting applications.
Table 1. Comparison of different models on two loads of short-term forecasting dataset. Comparison of different models on two loads of short-term forecasting dataset. Comparison of different models on two loads of short-term forecasting dataset.
Model | Load 1 | Load 2 | Load 3 |
MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE |
CNN | 3875 | 0.047 | 5506 | 3688 | 0.048 | 5454 | 3721 | 0.041 | 5124 |
DT | 4553 | 0.055 | 6809 | 4519 | 0.055 | 6765 | 4334 | 0.055 | 6579 |
LR | 3688 | 0.046 | 5974 | 3781 | 0.047 | 5803 | 3631 | 0.046 | 5730 |
LSTM | 3421 | 0.041 | 5313 | 3397 | 0.042 | 5206 | 3466 | 0.041 | 5169 |
MLP | 3391 | 0.042 | 5777 | 3578 | 0.041 | 5666 | 3882 | 0.047 | 5688 |
RF | 5131 | 0.066 | 7005 | 5231 | 0.061 | 6905 | 5331 | 0.067 | 6765 |
SBEM | 3033 | 0.039 | 5005 | 3285 | 0.040 | 5021 | 3117 | 0.041 | 4679 |
4.5. Analysis of Prediction Errors
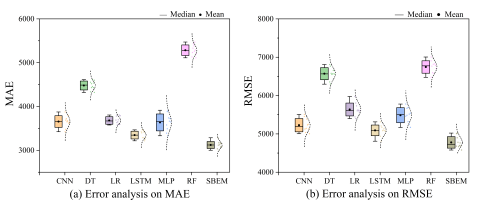
To provide a clear comparison of the predictive performance across the six base models and the SBEM approach, this study employs MAE and RMSE metrics across ten experimental trials for each method. The resulting data distributions are presented in box plot format in
Figure 3.
The visualization reveals that the SBEM's error distribution appears notably left-shifted on the plot, accompanied by a narrower interquartile range. This positioning indicates superior initial stability relative to the six base models. Furthermore, both mean and median for the SBEM's error metrics demonstrate lower values than those of the base models, suggesting enhanced accuracy in its predictive capabilities.
Figure 3. Error distribution comparison of seven models on MAE and RMSE. Error distribution comparison of seven models on MAE and RMSE.
4.6. Visualization Stability Analysis
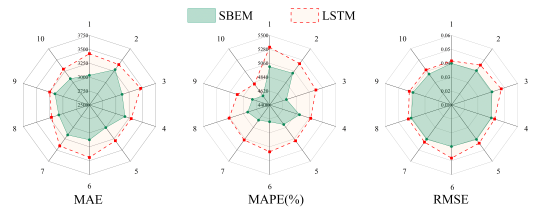
To further validate the reliability of SBEM, we conducted a comparative analysis across ten distinct nodes. Since the box plot analysis in
Figure 3 identified LSTM as the strongest base model, this section focuses on a comprehensive comparison between SBEM and LSTM using MAE, MAPE, and RMSE, as illustrated in the radar charts in
Figure 4.
The radar diagrams in
Figure 4 demonstrate that SBEM's performance indicators represented by green shading consistently fall within the range marked by LSTM's red dashed boundaries. This visual evidence confirms SBEM's superior accuracy across all evaluation metrics at the ten testing locations. Furthermore, SBEM exhibits tighter convergence patterns near the central region, as evidenced by both the reduced area coverage and other distinguishing features. When evaluated across diverse testing scenarios, SBEM maintains consistently low error rates, indicating enhanced capability to handle data variability and greater system stability. While LSTM outperforms the other five reference models, comprehensive analysis reveals SBEM's advantages in both predictive accuracy and operational reliability.
Figure 4. Performance comparison radar charts of SBEM and LSTM on three metrics. Performance comparison radar charts of SBEM and LSTM on three metrics.
5. Conclusion
This study proposes a robust heterogeneous ensemble learning framework to address the inherent volatility and non-stationarity challenges in short-term nodal electricity load forecasting. The proposed framework establishes a diverse forecasting repository incorporating six distinct fundamental models: CNN, LSTM, DT, LR, MLP, and RF. Furthermore, utilizing a meta-learning strategy based on stacking methodology, the system successfully integrates multi-dimensional characteristics to enhance prediction precision.
An extensive evaluation was conducted across ten distinct electricity distribution nodes to validate the efficacy of the proposed methodology. Experimental results demonstrate that the SBEM surpasses all base models across three key metrics: MAE, MAPE, and RMSE. Detailed error distribution examination through boxplot visualization reveals SBEM not only achieves the lowest average error values but also exhibits significantly enhanced stability, as evidenced by its narrower interquartile range compared to alternative models. Furthermore, radar chart representations confirm SBEM consistently outperforms the strongest base model, LSTM, across all examined nodes, highlighting its exceptional capability to handle data variability.
Future research directions encompass broadening model's applicability to diverse energy sector scenarios, such as forecasting renewable energy output. Additionally, efforts will focus on enhancing the model's predictive accuracy and operational reliability for practical power grid management.
Abbreviations
STLF | Short-Term Load Forecasting |
LR | Logistic Regression |
DT | Decision Tree |
RF | Random Forest |
MLP | Multilayer Perceptron |
CNN | Convolutional Neural Network |
LSTM | Long Short-Term Memory |
SBEM | Stacking-Based Ensemble Model |
ARIMA | Autoregressive Integrated Moving Average |
ES | Exponential Smoothing |
MLR | Multiple Linear Regression |
SVM | Support Vector Machine |
MAE | Mean Absolute Error |
MAPE | Mean Absolute Percentage Error |
RMSE | Root Mean Square Error |
Author Contributions
Qifan Peng: Methodology, Visualization, Writing – original draft
Kang Jiang: Conceptualization, Writing – review & editing
Zixuan Dai: Project administration, Writing – review & editing
Data Availability Statement
The data which support the findings of this study can be found at: https://www.dropbox.com/S/No9r15m9nschl63/Data.zip?dl=0
Conflicts of Interest
The authors declare no conflicts of interest.
References
| [1] |
Xu, H. Y., Zhang, Y., & Zhao, Y. (2023). Short-term electricity load forecasting based on ensemble empirical mode decomposition and long short-term memory neural network. In Proceedings of the 2023 IEEE International Conference on Energy Internet (ICEI), October 20-22, Shenyang, China, pp. 271-275.
https://doi.org/10.1109/ICEI60179.2023.00058
|
| [2] |
Goel, L., Wu, Q. W., & Wang, P. (2010). Fuzzy logic-based direct load control of air conditioning loads considering nodal reliability characteristics in restructured power systems. Electric Power Systems Research, 80(1), 98-107.
https://doi.org/10.1016/j.epsr.2009.08.009
|
| [3] |
Bunn, D. W. (1996). Non-traditional methods of forecasting. European Journal of Operational Research, 92(3), 528-536.
https://doi.org/10.1016/0377-2217(96)00006-9
|
| [4] |
Aguilar Madrid, E., & Antonio, N. (2021). Short-term electricity load forecasting with machine learning. Information, 12(2), 50.
https://doi.org/10.3390/info12020050
|
| [5] |
Lim, B., & Zohren, S. (2021). Time-series forecasting with deep learning: A survey. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 379(2194), 20200209.
https://doi.org/10.1098/rsta.2020.0209
|
| [6] |
Breckling, B. (2002). Individual-based modelling potentials and limitations. The Scientific World JOURNAL, 2, 1044-1062.
https://doi.org/10.1100/tsw.2002.179
|
| [7] |
Krogh, A., & Vedelsby, J. (1994). Neural network ensembles, cross validation, and active learning. In Proceedings of the 7th International Conference on Neural Information Processing Systems (NIPS), November 28-December 1, Denver, USA, pp. 231-238.
|
| [8] |
Makridakis, S., Wheelwright, S. C., & Hyndman, R. J. (1998). Forecasting: Methods and Applications (3rd ed.). John Wiley & Sons.
|
| [9] |
Zhang, G. P. (2003). Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing, 50, 159-175.
https://doi.org/10.1016/S0925-2312(01)00702-0
|
| [10] |
Suganthi, L., & Samuel, A. A. (2012). Energy models for demand forecasting—A review. Renewable and Sustainable Energy Reviews, 16(2), 1223-1240.
https://doi.org/10.1016/j.rser.2011.08.014
|
| [11] |
Almazrouee, A. I., Almeshal, A. M., Almutairi, A. S., Alenezi, M. R., & Alhajeri, S. N. (2020). Long-term forecasting of electrical loads in Kuwait using Prophet and Holt-Winters models. Applied Sciences, 10(16), 5627.
https://doi.org/10.3390/app10165627
|
| [12] |
Uyanık, G. K., & Güler, N. (2013). A study on multiple linear regression analysis. Procedia-Social and Behavioral Sciences, 106, 234-240.
https://doi.org/10.1016/j.sbspro.2013.12.027
|
| [13] |
Fumo, N., & Biswas, M. A. R. (2015). Regression analysis for prediction of residential energy consumption. Renewable and Sustainable Energy Reviews, 47, 332-343.
https://doi.org/10.1016/j.rser.2015.03.035
|
| [14] |
Akhtar, S., Shahzad, S., Zaheer, A., Ullah, H. S., Kilic, H., Gono, R., Jasiński, M., & Leonowicz, Z. (2023). Short-term load forecasting models: A review of challenges, progress, and the road ahead. Energies, 16(10), 4060.
https://doi.org/10.3390/en16104060
|
| [15] |
Baliyan, A., Gaurav, K., & Mishra, S. K. (2015). A review of short term load forecasting using artificial neural network models. Procedia Computer Science, 48, 121-125.
https://doi.org/10.1016/j.procs.2015.04.160
|
| [16] |
Zhou, Y., Liu, T. Y., & Yang, E. K. (2024). Machine learning model based on improved DBO algorithm optimized SVM. In Proceedings of the 2024 6th International Conference on Natural Language Processing (ICNLP), March 22-24, Xi'an, China, pp. 162-168.
https://doi.org/10.1109/ICNLP60986.2024.10692711
|
| [17] |
Magalhães, B., Bento, P., Pombo, J., Calado, M. R., & Mariano, S. (2024). Short-term load forecasting based on optimized random forest and optimal feature selection. Energies, 17(8), 1926.
https://doi.org/10.3390/en17081926
|
| [18] |
Amalou, I., Mouhni, N., & Abdali, A. (2024). CNN-LSTM architectures for non-stationary time series: Decomposition approach. In Proceedings of the 2024 International Conference on Global Aeronautical Engineering and Satellite Technology (GAST), April 24-26, Marrakesh, Morocco, pp. 1-5.
https://doi.org/10.1109/GAST60528.2024.10520774
|
| [19] |
Yoon, N., Lee, S., Kim, S. K., Park, C., Kim, T., & Jin, H. (2024). Energy consumption prediction using CNN-LSTM models: A time series big data analysis of electricity, heating, hot water, and water. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), November 3-6, Da Nang, Vietnam, pp. 1-4.
https://doi.org/10.1109/ICCE-Asia63397.2024.10774020
|
| [20] |
Alam, S., Dubey, A., & Bisen, D. (2025). An ensemble-based framework for enhanced missing data imputation. In Proceedings of the 2025 IEEE 14th International Conference on Communication Systems and Network Technologies (CSNT), March 7-9, Bhopal, India, pp. 647-651.
https://doi.org/10.1109/CSNT64827.2025.10967640
|
Cite This Article
-
ACS Style
Peng, Q.; Jiang, K.; Dai, Z. Short-Term Load Forecasting via Heterogeneous Ensemble Learning: A Study on Cross-Node Accuracy and Stability. Am. J. Energy Eng. 2026, 14(1), 9-17. doi: 10.11648/j.ajee.20261401.12
 Copy
|
Copy
|
 Download
Download
AMA Style
Peng Q, Jiang K, Dai Z. Short-Term Load Forecasting via Heterogeneous Ensemble Learning: A Study on Cross-Node Accuracy and Stability. Am J Energy Eng. 2026;14(1):9-17. doi: 10.11648/j.ajee.20261401.12
Copy
|
Download
-
@article{10.11648/j.ajee.20261401.12,
author = {Qifan Peng and Kang Jiang and Zixuan Dai},
title = {Short-Term Load Forecasting via Heterogeneous Ensemble Learning: A Study on Cross-Node Accuracy and Stability},
journal = {American Journal of Energy Engineering},
volume = {14},
number = {1},
pages = {9-17},
doi = {10.11648/j.ajee.20261401.12},
url = {https://doi.org/10.11648/j.ajee.20261401.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajee.20261401.12},
abstract = {Short-term load forecasting (STLF) serves as a fundamental basis for the efficient operation of smart grids and energy management systems. Accurate nodal-level load prediction plays a vital role in optimizing power dispatching, reducing operational costs, and enhancing grid security. Variations in user behavior patterns, geographical location, and equipment characteristics among different electricity nodes typically result in load profiles that exhibit pronounced volatility and non-stationarity. Traditional single model forecasting approaches are highly sensitive to data distribution and often struggle to maintain consistently high predictive accuracy across all nodes. Specifically, individual models frequently lack the generalization capability required for diverse load types, leading to significant error variability when applied to nodes with contrasting properties. To address these limitations, this study proposes a highly robust heterogeneous ensemble learning framework. First, a forecasting repository comprising six differentiated base models is constructed to accommodate diversity in model errors. Subsequently, a stacking-based meta-learning strategy is applied to integrate the outputs of the base models, enabling the extraction of multi-dimensional temporal features. To comprehensively validate the effectiveness of the proposed method, extensive comparative experiments are conducted using datasets from ten electricity nodes with diverse distribution characteristics. Experimental results demonstrate that the ensemble model significantly outperforms the base models in terms of accuracy while exhibiting superior stability across various nodes.},
year = {2026}
}
Copy
|
Download
-
TY - JOUR
T1 - Short-Term Load Forecasting via Heterogeneous Ensemble Learning: A Study on Cross-Node Accuracy and Stability
AU - Qifan Peng
AU - Kang Jiang
AU - Zixuan Dai
Y1 - 2026/01/31
PY - 2026
N1 - https://doi.org/10.11648/j.ajee.20261401.12
DO - 10.11648/j.ajee.20261401.12
T2 - American Journal of Energy Engineering
JF - American Journal of Energy Engineering
JO - American Journal of Energy Engineering
SP - 9
EP - 17
PB - Science Publishing Group
SN - 2329-163X
UR - https://doi.org/10.11648/j.ajee.20261401.12
AB - Short-term load forecasting (STLF) serves as a fundamental basis for the efficient operation of smart grids and energy management systems. Accurate nodal-level load prediction plays a vital role in optimizing power dispatching, reducing operational costs, and enhancing grid security. Variations in user behavior patterns, geographical location, and equipment characteristics among different electricity nodes typically result in load profiles that exhibit pronounced volatility and non-stationarity. Traditional single model forecasting approaches are highly sensitive to data distribution and often struggle to maintain consistently high predictive accuracy across all nodes. Specifically, individual models frequently lack the generalization capability required for diverse load types, leading to significant error variability when applied to nodes with contrasting properties. To address these limitations, this study proposes a highly robust heterogeneous ensemble learning framework. First, a forecasting repository comprising six differentiated base models is constructed to accommodate diversity in model errors. Subsequently, a stacking-based meta-learning strategy is applied to integrate the outputs of the base models, enabling the extraction of multi-dimensional temporal features. To comprehensively validate the effectiveness of the proposed method, extensive comparative experiments are conducted using datasets from ten electricity nodes with diverse distribution characteristics. Experimental results demonstrate that the ensemble model significantly outperforms the base models in terms of accuracy while exhibiting superior stability across various nodes.
VL - 14
IS - 1
ER -
Copy
|
Download