In recent years, since deep learning technology have been applied to handwritten text recognition, the need for handwritten document image Datasets has been growing more and more. In particular, the development of the dataset is of great significance for improving performance of handwritten Korean text recognition because no dataset for handwritten Korean text recognition has been published. In this paper, we present the “RanPil”, a new training and performance evaluation dataset for handwritten Korean text recognition, which consists of a total of 8,600 pages of images (182,000 text lines and 4,300,000 characters) written by 1,804 people. We evaluate writing- diversity of handwritten document images, such as text line spacing, text line slope, character size, word spacing, and character compactness. In addition, we propose an MOS (Mean Opinion Score) evaluation method for the scrawl-level. Finally, we evaluate the performance of TrOCR based on vision encoder and decoder with a test dataset classified by the scrawl-levels.
| Published in | International Journal on Data Science and Technology (Volume 11, Issue 2) |
| DOI | 10.11648/j.ijdst.20251102.12 |
| Page(s) | 27-34 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Deep Learning Technology, Handwritten Korean Dataset, HTR (Handwritten Text Recognition)
dataset name | writers | images | text lines | words | characters | classes | online/offline | language |
|---|---|---|---|---|---|---|---|---|
IAM [1] | 400 | 1 539 | 9 285 | 89 896 | 86 227 | 81 | offline | English |
IAM-OnDB [9] | 221 | - | 13 049 | - | 86 272 | 81 | online | English |
RIMES [2] | 1 300 | 1 600 | 12 111 | 60 000 | - | 79 | offline | French |
READ [14] | - | 1 962 | 10 550 | - | - | 93 | offline | German |
KHATT [3] | 1 000 | - | - | - | - | 49 | offline | Arabic |
Kondate [8] | 100 | - | 12 232 | - | 130 956 | 1 106 | online | Japanese |
HIT-MW [4] | 780 | - | 8 664 | - | 186 444 | 3 041 | offline | Chinese |
CASIA-HWDB 2.0~2.2 [7] | 1 019 | - | 52 230 | - | 1 344 414 | 2 703 | offline | Chinese |
SCUT-EPT [5] | 2 986 | - | 100 000 | - | 2 534 322 | 4 250 | offline | Chinese |
HCUT-HCCDoc [6] | - | 116 000 | 1 150 000 | 6 109 | offline | Chinese |
character type | characters | words | text lines | images | ||||
|---|---|---|---|---|---|---|---|---|
classes | Korean | English | digits | symbols | ||||
1 301 | 1 198 | 42 | 10 | 51 | 4.3M | 1.2M | 182K | 8.6K |
Category 1 | Category 2 | Category 3 | Category 4 | Total | |
|---|---|---|---|---|---|
Images | 160 | 486 | 300 | 54 | 1000 |
CER (%) | 5.3 | 7.2 | 16.8 | 28.5 | 10.93 |
MOS | Mean Opinion Score |
HTR | Handwritten Text Recognition |
| [1] | U. Marti and H. Bunke, “The IAM-database: an English sentence database for offline handwriting recognition”, International Journal on Document Analysis and Recognition, IJDAR, vol. 5, no. 1, pp. 39–46, 2002. |
| [2] | E. Grosicki, M. Carr´e, J. M. Brodin, and E. Geoffrois, “RIMES evaluation campaign for handwritten mail processing”, International Conference on Document Analysis and Recognition. ICDAR, pp. 941–945, 2009. |
| [3] | S. A. Mahmoud et al., ‘‘KHATT: Arabic offline handwritten text database,’’ in Proc. Int. Conf. Frontiers Handwriting Recognit. (ICFHR), pp. 449–454, 2012. |
| [4] | T. Su, T. Zhang, D. Guan, “Hit-mw dataset for offline Chinese handwritten text recognition”, in: Proceedings of International Workshop on Frontiers in Hand- writing Recognition (IWFHR), Citeseer, 2006. |
| [5] | Y. Zhu, Z. Xie, L. Jin, X. Chen, Y. Huang, and M. Zhang, “Scut-ept: New dataset and benchmark for offline Chinese text recognition in examination paper”, IEEE. Access, vol. 7, pp. 370–382, 2018. |
| [6] | H. Zhang, L. Liang, L. Jin, “SCUT-HCCDoc: A new benchmark dataset of handwritten Chinese text in unconstrained camera-captured documents”, Pattern Recognition, vol. 108, 2020. |
| [7] | C.-L. Liu, F. Yin, D.-H. Wang, and Q.-F. Wang, ‘‘CASIA online and offline Chinese handwriting databases,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), pp. 37–41, 2011. |
| [8] | T. Matsushita and M. Nakagawa, ‘‘A database of on-line handwritten mixed objects named ‘Kondate,’’’ in Proc. 14th Int. Conf. Frontiers Handwriting Recognit. (ICFHR), pp. 369–374, 2014. |
| [9] | M. Liwicki and H. Bunke, ‘‘IAM-OnDB—An on-line English sentence database acquired from handwritten text on a whiteboard,’’ in Proc. 8thInt. Conf. Document Anal. Recognit., pp. 956–961, 2005. |
| [10] | M. Li, T. Lv, J. Chen, L. Cui, Y. Lu, Dinei Florencio, C. Zhang, Z. Li, and Furu Wei. (2021). Trocr: Transformer-based optical character recognition with pre-trained models. [Online]. Available: |
| [11] | Denis Coquenet, Clément Chatelain, and Thierry Paquet. (2021)., End-to-end Handwritten Paragraph Text Recognition Using a Vertical Attention Network, [Online]. Available: |
| [12] | Denis Coquenet et al. (2023). Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition, [Online]. Available: |
| [13] | Masato Fujitake. (2023). DTrOCR: Decoder-only Transformer for Optical Character Recognition, [Online]. Available: |
| [14] | Sanchez, J. A., V. Romero, A. H. Toselli, and E. Vidal, “ICFHR2016 competition on handwritten text recognition on the READ dataset”, In Proceedings of the International Conference on Frontiers in Handwriting Recognition. ICFHR, pp. 630-635, 2016. |
| [15] | Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, [Online]. Available: |
| [16] | Liu, Y. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach, [Online]. Available: |
APA Style
O, H., Kim, M., Pak, I., Choe, U., O, C. (2025). RanPil: New Dataset and Benchmark for Offline Handwritten Korean Text Recognition. International Journal on Data Science and Technology, 11(2), 27-34. https://doi.org/10.11648/j.ijdst.20251102.12
ACS Style
O, H.; Kim, M.; Pak, I.; Choe, U.; O, C. RanPil: New Dataset and Benchmark for Offline Handwritten Korean Text Recognition. Int. J. Data Sci. Technol. 2025, 11(2), 27-34. doi: 10.11648/j.ijdst.20251102.12
@article{10.11648/j.ijdst.20251102.12,
author = {Hyon-Gwang O and Myong-Chol Kim and Il-Nam Pak and Un-Hyok Choe and Chol-Jun O},
title = {RanPil: New Dataset and Benchmark for Offline Handwritten Korean Text Recognition
},
journal = {International Journal on Data Science and Technology},
volume = {11},
number = {2},
pages = {27-34},
doi = {10.11648/j.ijdst.20251102.12},
url = {https://doi.org/10.11648/j.ijdst.20251102.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijdst.20251102.12},
abstract = {In recent years, since deep learning technology have been applied to handwritten text recognition, the need for handwritten document image Datasets has been growing more and more. In particular, the development of the dataset is of great significance for improving performance of handwritten Korean text recognition because no dataset for handwritten Korean text recognition has been published. In this paper, we present the “RanPil”, a new training and performance evaluation dataset for handwritten Korean text recognition, which consists of a total of 8,600 pages of images (182,000 text lines and 4,300,000 characters) written by 1,804 people. We evaluate writing- diversity of handwritten document images, such as text line spacing, text line slope, character size, word spacing, and character compactness. In addition, we propose an MOS (Mean Opinion Score) evaluation method for the scrawl-level. Finally, we evaluate the performance of TrOCR based on vision encoder and decoder with a test dataset classified by the scrawl-levels.
},
year = {2025}
}
TY - JOUR T1 - RanPil: New Dataset and Benchmark for Offline Handwritten Korean Text Recognition AU - Hyon-Gwang O AU - Myong-Chol Kim AU - Il-Nam Pak AU - Un-Hyok Choe AU - Chol-Jun O Y1 - 2025/06/20 PY - 2025 N1 - https://doi.org/10.11648/j.ijdst.20251102.12 DO - 10.11648/j.ijdst.20251102.12 T2 - International Journal on Data Science and Technology JF - International Journal on Data Science and Technology JO - International Journal on Data Science and Technology SP - 27 EP - 34 PB - Science Publishing Group SN - 2472-2235 UR - https://doi.org/10.11648/j.ijdst.20251102.12 AB - In recent years, since deep learning technology have been applied to handwritten text recognition, the need for handwritten document image Datasets has been growing more and more. In particular, the development of the dataset is of great significance for improving performance of handwritten Korean text recognition because no dataset for handwritten Korean text recognition has been published. In this paper, we present the “RanPil”, a new training and performance evaluation dataset for handwritten Korean text recognition, which consists of a total of 8,600 pages of images (182,000 text lines and 4,300,000 characters) written by 1,804 people. We evaluate writing- diversity of handwritten document images, such as text line spacing, text line slope, character size, word spacing, and character compactness. In addition, we propose an MOS (Mean Opinion Score) evaluation method for the scrawl-level. Finally, we evaluate the performance of TrOCR based on vision encoder and decoder with a test dataset classified by the scrawl-levels. VL - 11 IS - 2 ER -
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People's Republic of Korea

Figure 1.
Shows different examples of writing diversity.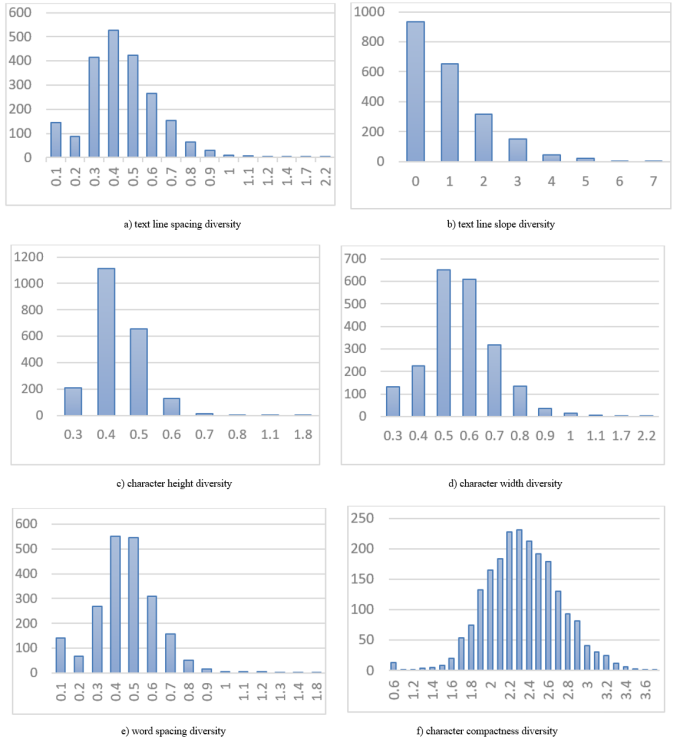
Figure 2.
Analysis of writing diversity in “RanPil”.
Figure 3. Examples of handwritten images according to the scrawl-level.

Figure 4. Catrgory-specific examples of the “RanPil” test data.
Information

