Machine learning has become a powerful tool in forecasting, offering greater accuracy than traditional human predictions in today’s data-driven world. The capability of machine learning to predict future trends has significant implications for key sectors such as finance, healthcare, and supply chain management. In this study, ARIMA/SARIMA (AutoRegressive Integrated Moving Average/Seasonal AutoRegressive Integrated Moving Average), alongside Prophet, a scalable forecasting tool developed by Facebook based on a generalized additive model, are considered. These models are applied to predict the demand for antidiabetic drugs. The records were collected by the Australian Health Insurance Commission. This dataset was sourced from Medicare Australia. The study evaluates the performance of these models based on their Mean Absolute Error (MAE), a key metric for assessing forecast accuracy. Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) are also considered. The outcome of the comparative analysis shows that the Prophet model outperformed both ARIMA and SARIMA models, achieving an MAE of 0.74, which is significantly lower than the MAE values of 2.18 and 3.02 obtained by SARIMA and ARIMA, respectively. Prophet's superior performance shows its effectiveness in handling complex, non-linear trends and seasonal patterns often observed in real-world time series data. This research contributes to the growing knowledge of machine learning-based forecasting and shows the importance of advanced models like Prophet in optimizing business operations and driving innovation. The findings from this research offer valuable guidance for data experts, analysts, and researchers in selecting the best forecasting methods for reliable predictions.
| Published in | Research & Development (Volume 5, Issue 4) |
| DOI | 10.11648/j.rd.20240504.13 |
| Page(s) | 110-120 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
AutoRegressive Integrated Moving Average (ARIMA), Seasonal AutoRegressive Integrated Moving Average (SARIMA), Mean Absolute Percentage Error (MAPE), Prophet, Time Series Forecasting, Comparative Analysis
Value | |
|---|---|
ADF Statistics | 3.145185689306735 |
p- value | 1.0 |
Number of Lags Used | 15 |
Number of Observations | 188 |
Critical Values | 1%: -3.465620397124192 5%: -2.8770397560752436 10%: -2.5750324547306476 |
Dependent variable | Values |
|---|---|
Total number of observations used in the analysis | 169 |
Model specifications | SARIMAX(3, 1, 3)x(3, 1, 3, 12), indicating a seasonal and non-seasonal order of (3, 1, 3) and (3, 1, 3, 12) respectively |
log likelihood of the model | -125.920 |
Akaike Information Criterion (AIC) | 277.841 |
Bayesian Information Criterion (BIC) | 317.489 |
Hannan-Quinn Information Criterion (HQIC) | 293.944 |
ds | yhat | yhat_lower | yhat_upper | |
|---|---|---|---|---|
201 | 2008-04-01 | 22.195313 | 20.914156 | 23.543719 |
202 | 2008-05-01 | 22.575389 | 21.302224 | 23.803814 |
203 | 2008-06-01 | 22.148415 | 20.802760 | 23.391756 |
204 | 2008-06-02 | 21.477172 | 20.162868 | 22.749761 |
205 | 2008-06-03 | 20.848034 | 19.475679 | 22.144559 |
206 | 2008-06-04 | 20.272289 | 18.942728 | 21.561791 |
207 | 2008-06-05 | 19.759586 | 18.391037 | 21.124836 |
208 | 2008-06-06 | 19.317742 | 18.003627 | 20.687164 |
209 | 2008-06-07 | 18.952615 | 17.711169 | 20.339748 |
210 | 2008-06-08 | 18.668027 | 17.366279 | 20.009852 |
ds | ARIMA_predictions | SARIMA predictions | PROPHET predictions (yhat) | |
|---|---|---|---|---|
233 | 2008-07-01 | 18.868517 | 20.666992 | 23.495457 |
234 | 2008-07-02 | 19.079705 | 20.665763 | 23.615460 |
235 | 2008-07-03 | 20.342761 | 21.313098 | 23.716462 |
236 | 2008-07-04 | 19.584552 | 22.557885 | 23.802352 |
237 | 2008-07-05 | 21.170749 | 22.786816 | 23.877175 |
238 | 2008-07-06 | 21.869748 | 24.273169 | 23.944934 |
239 | 2008-07-07 | 23.048193 | 27.043418 | 24.009401 |
240 | 2008-07-08 | 16.434465 | 17.595999 | 24.073943 |
241 | 2008-07-09 | 16.791910 | 19.208757 | 24.141377 |
242 | 2008-07-10 | 18.201320 | 19.747515 | 24.213838 |
SARIMA | Seasonal Auto Regressive Integrated Moving Average |
ARIMA | AutoRegressive Integrated Moving Average |
MA | Moving Average |
AR | Auto Regression |
AIC | Akaike Information Criterion |
MAPE | Mean Absolute Percentage Error |
MAE | Mean Absolute Error |
RMSE | Root Mean Square Error |
ANN | Artificial Neural Networks |
ADF | Augmented Dickey-Fuller |
ACF | Auto Correlation Functions |
SARIMAX | Seasonal Autoregressive Integrated Moving Average with Exogenous Regressors |
CV(RMSE) | Coefficient of the Variation of the Root Mean Square Error |
NME | Normalized Mean Error |
| [1] | Bharatpur, A. S., A LITERATURE REVIEW ON TIME SERIES FORECASTING METHODS. 2022. |
| [2] | Taylor, S. J. and B. Letham, Forecasting at Scale. PeerJ Preprints, 27 Sept. 2017. |
| [3] | Yenidogan, I., et al., Bitcoin Forecasting Using ARIMA and PROPHET, in 2018 3rd International Conference on Computer Science and Engineering (UBMK). 2018. p. 621-624. |
| [4] | Khashei, M., M. Bijari, and S. R. Hejazi, Combining seasonal ARIMA models with computational intelligence techniques for time series forecasting. Soft Computing, 2012. 16(6): p. 1091-1105. |
| [5] | F. V. Ferdinand, T. H. Santoso and K. V. I. Saputra, "Performance Comparison Between Facebook Prophet and SARIMA on Indonesian Stock," 2023 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, Singapore, 2023, pp. 1-5, |
| [6] | Wang Y, Yan Z, Wang D, Yang M, Li Z, Gong X, Wu D, Zhai L, Zhang W, Wang Y. Prediction and analysis of COVID-19 daily new cases and cumulative cases: times series forecasting and machine learning models. BMC Infect Dis. 2022 May 25; 22(1): 495. |
| [7] | Christophorus Beneditto Aditya Satrio, William Darmawan, Bellatasya Unrica Nadia, Novita Hanafiah, Time series analysis and forecasting of coronavirus disease in Indonesia using ARIMA model and PROPHET, Procedia ComputerScience, Volume 179, 2021, Pages 524-532, ISSN1877-0509, |
| [8] | Peixeiro, M. S. a. S., Time Series Forecasting in Python. 15 Nov. 2022. |
| [9] | Ali Hussein, Hussein, Mukhtar M. E. Mahmoud, and Haroun A. Eisa. 2023. “Performance Evaluation of ARIMA and FB-Prophet Forecasting Methods in the Context of Endemic Diseases: A Case Study of Gedaref State in Sudan”. EAI Endorsed Transactions on Smart Cities 7(2): e1. |
| [10] | Botchkarev, A., A New Typology Design of Performance Metrics to Measure Errors in Machine Learning Regression Algorithms. Interdisciplinary Journal of Information, Knowledge, and Management, 2019. 14: p. 045-076. |
| [11] | Vogt, M. R., Peter & Lauster, Moritz & Fuchs, Marcus & Mueller, Dirk., Selecting statistical indices for calibrating building energy models. Building and Environment. S144. |
| [12] | Hodson, Timothy O. (2022). Root-mean-square error (RMSE) or mean absolute error (MAE): when to use them or not. Geoscientific Model Development. 15. 5481-5487. |
| [13] | Nain N and Behera G 2019 A Comparative Study of Big Mart Sales Prediction 4th International Conference on Computer Vision and Image Processing (Jaipur: MNIT) p 4. |
| [14] | Vandeput, N. (2023, September 27). Forecast KPI: RMSE, MAE, MAPE & BiAS | Towards Data Science. Medium. |
APA Style
Kwarteng, S. B., Andreevich, P. A. (2024). Comparative Analysis of ARIMA, SARIMA and Prophet Model in Forecasting. Research & Development, 5(4), 110-120. https://doi.org/10.11648/j.rd.20240504.13
ACS Style
Kwarteng, S. B.; Andreevich, P. A. Comparative Analysis of ARIMA, SARIMA and Prophet Model in Forecasting. Res. Dev. 2024, 5(4), 110-120. doi: 10.11648/j.rd.20240504.13
AMA Style
Kwarteng SB, Andreevich PA. Comparative Analysis of ARIMA, SARIMA and Prophet Model in Forecasting. Res Dev. 2024;5(4):110-120. doi: 10.11648/j.rd.20240504.13
@article{10.11648/j.rd.20240504.13,
author = {Samuel Baffoe Kwarteng and Poguda Aleksey Andreevich},
title = {Comparative Analysis of ARIMA, SARIMA and Prophet Model in Forecasting
},
journal = {Research & Development},
volume = {5},
number = {4},
pages = {110-120},
doi = {10.11648/j.rd.20240504.13},
url = {https://doi.org/10.11648/j.rd.20240504.13},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.rd.20240504.13},
abstract = {Machine learning has become a powerful tool in forecasting, offering greater accuracy than traditional human predictions in today’s data-driven world. The capability of machine learning to predict future trends has significant implications for key sectors such as finance, healthcare, and supply chain management. In this study, ARIMA/SARIMA (AutoRegressive Integrated Moving Average/Seasonal AutoRegressive Integrated Moving Average), alongside Prophet, a scalable forecasting tool developed by Facebook based on a generalized additive model, are considered. These models are applied to predict the demand for antidiabetic drugs. The records were collected by the Australian Health Insurance Commission. This dataset was sourced from Medicare Australia. The study evaluates the performance of these models based on their Mean Absolute Error (MAE), a key metric for assessing forecast accuracy. Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) are also considered. The outcome of the comparative analysis shows that the Prophet model outperformed both ARIMA and SARIMA models, achieving an MAE of 0.74, which is significantly lower than the MAE values of 2.18 and 3.02 obtained by SARIMA and ARIMA, respectively. Prophet's superior performance shows its effectiveness in handling complex, non-linear trends and seasonal patterns often observed in real-world time series data. This research contributes to the growing knowledge of machine learning-based forecasting and shows the importance of advanced models like Prophet in optimizing business operations and driving innovation. The findings from this research offer valuable guidance for data experts, analysts, and researchers in selecting the best forecasting methods for reliable predictions.
},
year = {2024}
}
TY - JOUR T1 - Comparative Analysis of ARIMA, SARIMA and Prophet Model in Forecasting AU - Samuel Baffoe Kwarteng AU - Poguda Aleksey Andreevich Y1 - 2024/10/18 PY - 2024 N1 - https://doi.org/10.11648/j.rd.20240504.13 DO - 10.11648/j.rd.20240504.13 T2 - Research & Development JF - Research & Development JO - Research & Development SP - 110 EP - 120 PB - Science Publishing Group SN - 2994-7057 UR - https://doi.org/10.11648/j.rd.20240504.13 AB - Machine learning has become a powerful tool in forecasting, offering greater accuracy than traditional human predictions in today’s data-driven world. The capability of machine learning to predict future trends has significant implications for key sectors such as finance, healthcare, and supply chain management. In this study, ARIMA/SARIMA (AutoRegressive Integrated Moving Average/Seasonal AutoRegressive Integrated Moving Average), alongside Prophet, a scalable forecasting tool developed by Facebook based on a generalized additive model, are considered. These models are applied to predict the demand for antidiabetic drugs. The records were collected by the Australian Health Insurance Commission. This dataset was sourced from Medicare Australia. The study evaluates the performance of these models based on their Mean Absolute Error (MAE), a key metric for assessing forecast accuracy. Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) are also considered. The outcome of the comparative analysis shows that the Prophet model outperformed both ARIMA and SARIMA models, achieving an MAE of 0.74, which is significantly lower than the MAE values of 2.18 and 3.02 obtained by SARIMA and ARIMA, respectively. Prophet's superior performance shows its effectiveness in handling complex, non-linear trends and seasonal patterns often observed in real-world time series data. This research contributes to the growing knowledge of machine learning-based forecasting and shows the importance of advanced models like Prophet in optimizing business operations and driving innovation. The findings from this research offer valuable guidance for data experts, analysts, and researchers in selecting the best forecasting methods for reliable predictions. VL - 5 IS - 4 ER -
Faculty of Innovation Technology, National Research Tomsk State University, Tomsk State, Russian Federation
Biography: Baffoe Samuel Kwarteng is a graduate researcher at National Research Tomsk State University in the field of Applied Artificial Intelligence and Robotics.
Research Fields: Neural networks, Big Data, Computer Vision, Natural Language Processing, Machine Learning, Artificial Intelligence, Renewable Energy.
Faculty of Innovation Technology, National Research Tomsk State University, Tomsk State, Russian Federation
Biography: Poguda Aleksey Andreevich: a professor at the Department of Information Support of Innovative Activity within the Faculty of Innovative Technologies at the National Research Tomsk State University. He is a member of the Council of Young Scientists of TSU and the Leading Programmer of the Laboratory of Personal Computers and Multimedia Devices. Researcher ID: G-5548-2014 (Aleksey Poguda)
Research Fields: Neural networks, computer security, network security, big data, semantic text analysis
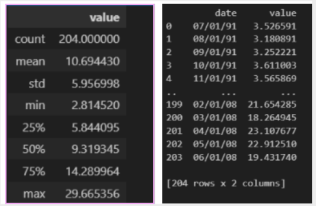
Figure 1. Shape and Description of Dataset.
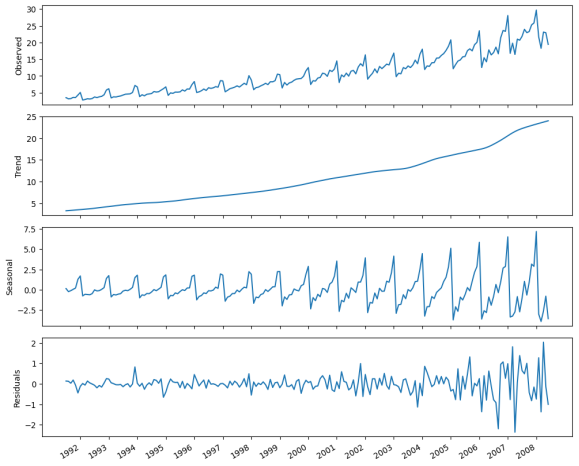
Figure 2. The decomposition of the monthly number of antidiabetic drug prescriptions in Australia between 1991 and 2008. The first plot illustrates the observed data. The second plot demonstrates the trend component, which exhibits a consistent increase over time. The third plot shows the seasonal component, which is distinctly observed as recurring through time. Finally, the last plot represents the residuals, which signify the variations in the data that cannot be explained by the trend or the seasonal component.
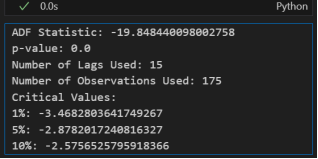
Figure 3. Augmented Dickey-Fuller Test.
Figure 4. An example of MA(1) process, produced using a number generator.
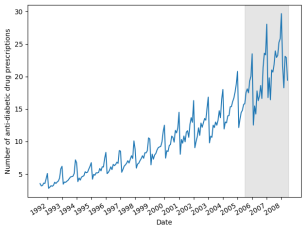
Figure 5. Train set and test split for antidiabetic drug dataset. The shaded area is the testing period.
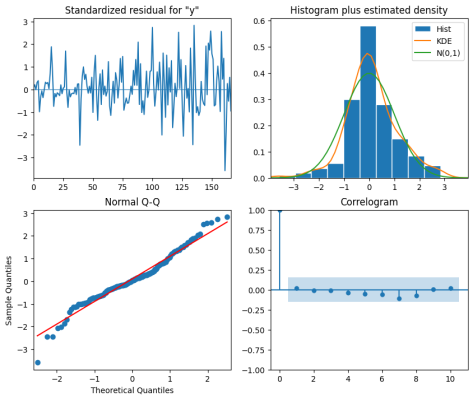
Figure 6. ARIMA diagnostic plot.
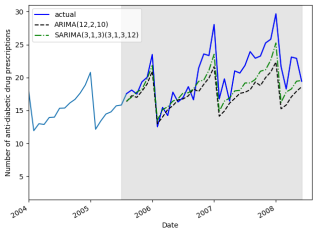
Figure 7. Actual and Predicted Drug Distribution using ARIMA and SARIMA Models.
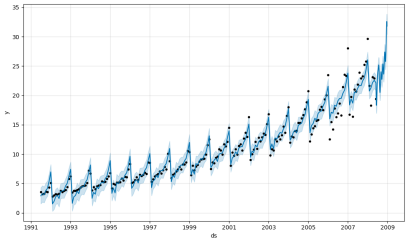
Figure 8. Forecasted Antidiabetic Drug Sales.
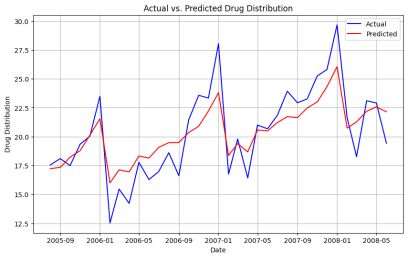
Figure 9. Actual vs. Predicted Drug Distribution.
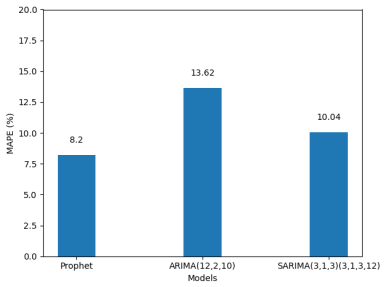
Figure 10. MAPE Evaluation.
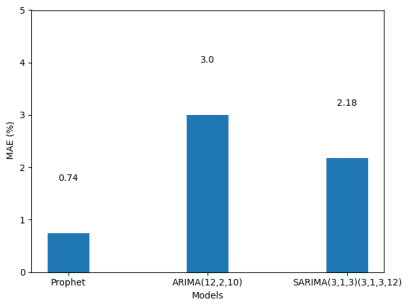
Figure 11. MAE Evaluation.
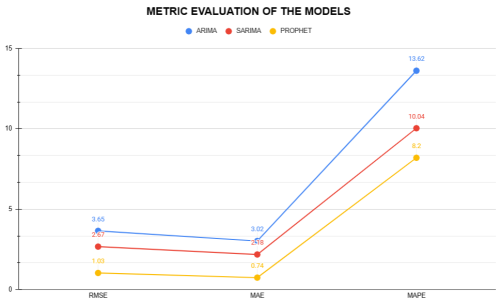
Figure 12. Metric Evaluation of the Models.
Information

