Foundation models (FMs) have the potential to revolutionize various fields, but their reliability is often compromised by hallucinations. This paper delves into the intricate nature of model hallucinations, exploring their root causes, mitigation strategies, and evaluation metrics. We provide a comprehensive overview of the challenges posed by hallucinations, including factual inaccuracies, logical inconsistencies, and the generation of fabricated content. To address these issues, we discuss a range of techniques, such as improving data quality, refining model architectures, and employing advanced prompting techniques. We also highlight the importance of developing robust evaluation metrics to detect and quantify hallucinations. By understanding the underlying mechanisms and implementing effective mitigation strategies, we can unlock the full potential of FMs and ensure their reliable and trustworthy operation. Foundation Models (FMs), such as large language models and multimodal transformers, have demonstrated transformative capabilities across a wide range of applications in artificial intelligence, including natural language processing, computer vision, and decision support systems. Despite their remarkable success, the reliability and trustworthiness of these models are frequently undermined by a phenomenon known as hallucination, the generation of outputs that are factually incorrect, logically inconsistent, or entirely fabricated. This study presents a comprehensive examination of model hallucinations, focusing on their underlying causes, mitigation approaches, and evaluation metrics for systematic detection. We begin by analyzing the root causes of hallucination, which span data-related factors such as bias, noise, and imbalance, as well as architectural and training issues like over-parameterization, poor generalization, and the lack of grounded reasoning. The paper categorizes hallucinations into factual, logical, and contextual types, illustrating how each arises in different stages of model inference and decision-making. We further discuss how prompt engineering, attention misalignment, and inadequate fine-tuning contribute to the persistence of erroneous model outputs. To mitigate these challenges, we explore a range of strategies, including improving data curation and preprocessing pipelines, integrating factual verification and retrieval-augmented mechanisms, and refining model architectures to enhance interpretability and context awareness. Techniques such as reinforcement learning with human feedback (RLHF), chain-of-thought prompting, and hybrid symbolic-neural approaches are highlighted for their potential in reducing hallucination rates while maintaining model fluency and adaptability. Furthermore, this work emphasizes the critical need for rigorous and standardized evaluation metrics capable of quantifying the severity, frequency, and impact of hallucinations. Metrics such as factual consistency scores, semantic similarity indices, and hallucination detection benchmarks are discussed as essential tools for assessing model reliability. Ultimately, this paper provides a structured understanding of model hallucinations as both a technical and ethical challenge in the deployment of Foundation Models. By elucidating their origins and presenting practical mitigation frameworks, we aim to advance the development of more transparent, accountable, and trustworthy AI systems. The insights presented herein contribute to ongoing efforts to ensure that Foundation Models not only achieve high performance but also uphold factual integrity and user trust across real-world applications.
| Published in | American Journal of Artificial Intelligence (Volume 10, Issue 1) |
| DOI | 10.11648/j.ajai.20261001.16 |
| Page(s) | 61-70 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
Hallucinations, Misleading Information, AI Model, Foundation Models
Title | Detect? | Mitigate? | Task(s) | Dataset | Evaluation Metric |
|---|---|---|---|---|---|
Citation: A Key to Building Responsible and Accountable Large Language Models (Huang and Chang, 2023) | ✓ | ✓ | N/A | N/A | N/A |
Zero-resource hallucination prevention for large language models (Lao et al., 2023) | ✓ | ✓ | Concept extraction, guessing, aggregation | Concept-7 | AUC, ACC, F1, PEA |
RARR: Researching and Revising What Language Models Say, Using Language Models (Gao et al., 2023) | ✓ | ✓ | Editing for Attribution | NQ, SQuAD, QReCC | Attributable to Idea-filled Sources (Castaño and Yang, 2007) |
Evaluating Object Hallucination in Large Vision-Language Models (Li et al., 2023e) | ✗ | ✓ | Image captioning | MSCOCO (Lin et al., 2014) | Caption Hallucination Assessment with Image Relevance (CHAIR) (Rohrbach et al., 2018) |
Detecting and Preventing Hallucinations in Large Vision Language Models (Gunjal et al., 2023) | ✓ | ✓ | Visual Question Answering (VQA) | M-HalDetect | Accuracy |
Plausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training (Dai et al., 2022) | ✗ | ✓ | Image captioning | CHAIR (Rohrbach et al., 2018) | CIDEr |
Let’s Think Frame by Frame: Evaluating Video Chain of Thought with Video Inference and Prediction (Himankahtala et al., 2023) | ✓ | ✗ | Video infilling, Scene prediction | Manual | N/A |
Putting People in Their Place: Affordance-Aware Human Insertion into Videos (Kulal et al., 2023) | ✗ | ✓ | Affordance prediction | Manual (2.4M video clips) | FID, PCKh |
VideoChat: Chat-Centric Video Understanding (Li et al., 2023c) | ✓ | ✓ | Visual dialogue | Manual | N/A |
Models See Hallucinations: Evaluating the Factuality in Video Captioning (Liu and Wan, 2023) | ✗ | ✓ | Video captioning | ActivityNet Captions (Krishna et al., 2017), YouCook2 (Zhou et al., 2017) | Factual consistency for Video Captioning (FactVC) |
LP-MusicCaps: LLM-based pseudo music captioning (Doh et al., 2023) | ✓ | ✓ | Audio captioning | LP-MusicCaps | BLEU-1 to 4 (B1–B4), METEOR (M), ROUGE-L |
Audio-Journey: Efficient Visual-LLM-aided Audio Encode Diffusion (Li et al., 2023a) | ✓ | ✓ | Classification | Manual | Mean Average Precision (mAP) |
| [1] | Ailin Deng, ZC and BH 2024,. ‘Seeing is believing: Mitigating hallucination in large visionlanguage models via clip-guided decoding.’ |
| [2] | Anthony Chen, PPSSHLKG 2023, ‘PURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions’, Computation and Language. |
| [3] | Fuxiao Liu, KLLLJWYY and LWang 2023, ‘Mitigating hallucination in large multi-modal models via robust instruction tuning. ’, In The Twelfth International Conference on Learning Representations. |
| [4] | Holy Lovenia, WDSCZJ and PF 2023, ‘Negative object presence evaluation (nope) to measure object hallucination in vision-language models’, arXiv preprint arXiv: 2310.05338. |
| [5] | Jian Zhang, YZ and FWu 2006, ‘Videobased facial expression hallucination: A two-level hierarchical fusion approach’, In International Conference on Advanced Concepts for Intelligent Vision Systems. |
| [6] | Jiaxi Cui, ZLYYBCLY 2023, ‘ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases’, Computation and Language. |
| [7] | Jiazhen Liu, and XLi 2024, ‘Phd: A prompted visual hallucination evaluation dataset’, arXiv preprint arXiv: 2403.11116. |
| [8] | Jie Huang, KC-CC 2024, ‘Citation: A Key to Building Responsible and Accountable Large Language Models’, Computation and Language. |
| [9] | Jing Wu, JH and NH n.d., ‘Hallucination improves the performance of unsupervised visual representation learning.’, Computer Vision and Pattern Recognition. |
| [10] | Jonghwan Mun, LYZRNX and BH 2019, ‘ Streamlined dense video captioning’, In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6588-6597. |
| [11] | KunChang Li, and YQ 2023, ‘Videochat: Chat-centric video understanding’, arXiv preprint arXiv: 2305.06355. |
| [12] | Luowei Zhou, CX and JC 2018, ‘Towards automatic learning of procedures from web instructional videos. ’, In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32. |
| [13] | Maitreya Suin and AN Rajagopalan. 2020, ‘An efficient framework for dense video captioning.’, In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 12039-12046. |
| [14] | Min, S, Krishna, K, Lyu, X, Lewis, M, Yih, W, Koh, P, Iyyer, M, Zettlemoyer, L & Hajishirzi, H 2023, ‘FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation’, in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Stroudsburg, PA, USA, pp. 12076-12100. |
| [15] | Niels Mündler, JHSJMV 2023, ‘Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation’, Computation and Language. |
| [16] | Potsawee Manakul, ALMJFG 2023, ‘SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models’, Computation and Language. |
| [17] | Qifan Yu, and YZhuang 2023, ‘Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data.’, arXiv preprint arXiv: 2311.13614. |
| [18] | Rombach, R, Blattmann, A, Lorenz, D, Esser, P & Ommer, B 2022, ‘High-Resolution Image Synthesis with Latent Diffusion Models’, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, pp. 10674-10685. |
| [19] | Shiping Yang, RSXW 2023, ‘A New Benchmark and Reverse Validation Method for Passage-level Hallucination Detection’. |
| [20] | Sumith Kulal, and KKS 2023, ‘Putting people in their place: Affordance-aware human insertion into scenes.’, In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17089-17099. |
| [21] | Vipula Rawte, ASAD 2023, ‘A Survey of Hallucination in “Large” Foundation Models’, AI Institute, University of South Carolina, USA. |
| [22] | Vladimir Iashin and Esa Rahtu 2020, ‘Multi-modal dense video captioning.’, In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp. 958-959. |
| [23] | Weilun Wu and Yang Gao. n.d., ‘A context-aware model with a pre-trained context encoder for dense video captioning. ’, In International Conference on Cyber Security, Artificial Intelligence, and Digital Economy (CSAIDE 2023), vol. 12718, pp. 387-396. |
| [24] | Wenliang Dai, ZLZJDS and PFung n.d., ‘ Plausible may not be faithful: Probing object hallucination in vision-language pre-training’, arXiv preprint arXiv: 2210.07688. |
| [25] | Xingyi Zhou, and CS 2024, ‘Streaming dense video captioning. ’, arXiv preprint arXiv: 2404.01297. |
| [26] | Xintong Wang, JPLDCB 2024a, ‘Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding’, Computer Vision and Pattern Recognition. |
| [27] | Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann 2024b, ‘Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding’. |
| [28] | Yifan Li, and J-RW 2023, ‘Evaluating object hallucination in large vision-language models’, arXiv preprint arXiv: 2305.10355. |
| [29] | Yue Zhang, 2023, ‘Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models’, Computation and Language. |
| [30] | Zhengzhuo Xu, and JGuo 2023, ‘Chartbench: A benchmark for complex visual reasoning in charts. ’, arXiv preprint arXiv: 2312.15915. |
| [31] | Ziwei Xu, SJ and MKankanhalli 2024. ‘Hallucination is inevitable: An innate limitation of large language models’. In Proceedings of the 31st ACM International Conference on Multimedia. |
APA Style
Samuel, D. R., Aderemi, A. A., Okechukwu, O. C., Peter, O., Sandra, D. I., et al. (2026). Understanding Model Hallucinations: Causes, Mitigation Strategies, and Evaluation Metrics for Detection. American Journal of Artificial Intelligence, 10(1), 61-70. https://doi.org/10.11648/j.ajai.20261001.16
ACS Style
Samuel, D. R.; Aderemi, A. A.; Okechukwu, O. C.; Peter, O.; Sandra, D. I., et al. Understanding Model Hallucinations: Causes, Mitigation Strategies, and Evaluation Metrics for Detection. Am. J. Artif. Intell. 2026, 10(1), 61-70. doi: 10.11648/j.ajai.20261001.16
AMA Style
Samuel DR, Aderemi AA, Okechukwu OC, Peter O, Sandra DI, et al. Understanding Model Hallucinations: Causes, Mitigation Strategies, and Evaluation Metrics for Detection. Am J Artif Intell. 2026;10(1):61-70. doi: 10.11648/j.ajai.20261001.16
@article{10.11648/j.ajai.20261001.16,
author = {Diarah Reuben Samuel and Adekunel Adefemi Aderemi and Osueke Christian Okechukwu and Onu Peter and Diarah Ifeyinwa Sandra and Ozichi Emuoyibofarhe and Olaomi Bimpe Agnes and Evoh Edwin Emeng},
title = {Understanding Model Hallucinations: Causes, Mitigation Strategies, and Evaluation Metrics for Detection},
journal = {American Journal of Artificial Intelligence},
volume = {10},
number = {1},
pages = {61-70},
doi = {10.11648/j.ajai.20261001.16},
url = {https://doi.org/10.11648/j.ajai.20261001.16},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajai.20261001.16},
abstract = {Foundation models (FMs) have the potential to revolutionize various fields, but their reliability is often compromised by hallucinations. This paper delves into the intricate nature of model hallucinations, exploring their root causes, mitigation strategies, and evaluation metrics. We provide a comprehensive overview of the challenges posed by hallucinations, including factual inaccuracies, logical inconsistencies, and the generation of fabricated content. To address these issues, we discuss a range of techniques, such as improving data quality, refining model architectures, and employing advanced prompting techniques. We also highlight the importance of developing robust evaluation metrics to detect and quantify hallucinations. By understanding the underlying mechanisms and implementing effective mitigation strategies, we can unlock the full potential of FMs and ensure their reliable and trustworthy operation. Foundation Models (FMs), such as large language models and multimodal transformers, have demonstrated transformative capabilities across a wide range of applications in artificial intelligence, including natural language processing, computer vision, and decision support systems. Despite their remarkable success, the reliability and trustworthiness of these models are frequently undermined by a phenomenon known as hallucination, the generation of outputs that are factually incorrect, logically inconsistent, or entirely fabricated. This study presents a comprehensive examination of model hallucinations, focusing on their underlying causes, mitigation approaches, and evaluation metrics for systematic detection. We begin by analyzing the root causes of hallucination, which span data-related factors such as bias, noise, and imbalance, as well as architectural and training issues like over-parameterization, poor generalization, and the lack of grounded reasoning. The paper categorizes hallucinations into factual, logical, and contextual types, illustrating how each arises in different stages of model inference and decision-making. We further discuss how prompt engineering, attention misalignment, and inadequate fine-tuning contribute to the persistence of erroneous model outputs. To mitigate these challenges, we explore a range of strategies, including improving data curation and preprocessing pipelines, integrating factual verification and retrieval-augmented mechanisms, and refining model architectures to enhance interpretability and context awareness. Techniques such as reinforcement learning with human feedback (RLHF), chain-of-thought prompting, and hybrid symbolic-neural approaches are highlighted for their potential in reducing hallucination rates while maintaining model fluency and adaptability. Furthermore, this work emphasizes the critical need for rigorous and standardized evaluation metrics capable of quantifying the severity, frequency, and impact of hallucinations. Metrics such as factual consistency scores, semantic similarity indices, and hallucination detection benchmarks are discussed as essential tools for assessing model reliability. Ultimately, this paper provides a structured understanding of model hallucinations as both a technical and ethical challenge in the deployment of Foundation Models. By elucidating their origins and presenting practical mitigation frameworks, we aim to advance the development of more transparent, accountable, and trustworthy AI systems. The insights presented herein contribute to ongoing efforts to ensure that Foundation Models not only achieve high performance but also uphold factual integrity and user trust across real-world applications.},
year = {2026}
}
TY - JOUR T1 - Understanding Model Hallucinations: Causes, Mitigation Strategies, and Evaluation Metrics for Detection AU - Diarah Reuben Samuel AU - Adekunel Adefemi Aderemi AU - Osueke Christian Okechukwu AU - Onu Peter AU - Diarah Ifeyinwa Sandra AU - Ozichi Emuoyibofarhe AU - Olaomi Bimpe Agnes AU - Evoh Edwin Emeng Y1 - 2026/02/02 PY - 2026 N1 - https://doi.org/10.11648/j.ajai.20261001.16 DO - 10.11648/j.ajai.20261001.16 T2 - American Journal of Artificial Intelligence JF - American Journal of Artificial Intelligence JO - American Journal of Artificial Intelligence SP - 61 EP - 70 PB - Science Publishing Group SN - 2639-9733 UR - https://doi.org/10.11648/j.ajai.20261001.16 AB - Foundation models (FMs) have the potential to revolutionize various fields, but their reliability is often compromised by hallucinations. This paper delves into the intricate nature of model hallucinations, exploring their root causes, mitigation strategies, and evaluation metrics. We provide a comprehensive overview of the challenges posed by hallucinations, including factual inaccuracies, logical inconsistencies, and the generation of fabricated content. To address these issues, we discuss a range of techniques, such as improving data quality, refining model architectures, and employing advanced prompting techniques. We also highlight the importance of developing robust evaluation metrics to detect and quantify hallucinations. By understanding the underlying mechanisms and implementing effective mitigation strategies, we can unlock the full potential of FMs and ensure their reliable and trustworthy operation. Foundation Models (FMs), such as large language models and multimodal transformers, have demonstrated transformative capabilities across a wide range of applications in artificial intelligence, including natural language processing, computer vision, and decision support systems. Despite their remarkable success, the reliability and trustworthiness of these models are frequently undermined by a phenomenon known as hallucination, the generation of outputs that are factually incorrect, logically inconsistent, or entirely fabricated. This study presents a comprehensive examination of model hallucinations, focusing on their underlying causes, mitigation approaches, and evaluation metrics for systematic detection. We begin by analyzing the root causes of hallucination, which span data-related factors such as bias, noise, and imbalance, as well as architectural and training issues like over-parameterization, poor generalization, and the lack of grounded reasoning. The paper categorizes hallucinations into factual, logical, and contextual types, illustrating how each arises in different stages of model inference and decision-making. We further discuss how prompt engineering, attention misalignment, and inadequate fine-tuning contribute to the persistence of erroneous model outputs. To mitigate these challenges, we explore a range of strategies, including improving data curation and preprocessing pipelines, integrating factual verification and retrieval-augmented mechanisms, and refining model architectures to enhance interpretability and context awareness. Techniques such as reinforcement learning with human feedback (RLHF), chain-of-thought prompting, and hybrid symbolic-neural approaches are highlighted for their potential in reducing hallucination rates while maintaining model fluency and adaptability. Furthermore, this work emphasizes the critical need for rigorous and standardized evaluation metrics capable of quantifying the severity, frequency, and impact of hallucinations. Metrics such as factual consistency scores, semantic similarity indices, and hallucination detection benchmarks are discussed as essential tools for assessing model reliability. Ultimately, this paper provides a structured understanding of model hallucinations as both a technical and ethical challenge in the deployment of Foundation Models. By elucidating their origins and presenting practical mitigation frameworks, we aim to advance the development of more transparent, accountable, and trustworthy AI systems. The insights presented herein contribute to ongoing efforts to ensure that Foundation Models not only achieve high performance but also uphold factual integrity and user trust across real-world applications. VL - 10 IS - 1 ER -
Mechatronics Engineering Programme, Bowen University, Iwo, Nigeria
Mechatronics Engineering Department, Federal University, Oye Ekiti, Nigeria
Mechatronics Engineering Programme, Bowen University, Iwo, Nigeria
Mechanical/Mechatronics Engineering Department, Pan Atinatic University, Lagos, Nigeria
Accounting and Finance Programme, Bowen University, Iwo, Nigeria
Computer Science Programme, Bowen University, Iwo, Nigeria
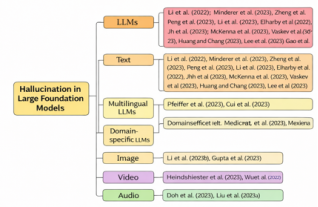
Figure 1. Taxonomy for Hallucination in large foundation models. (Vipula et al. (2023).
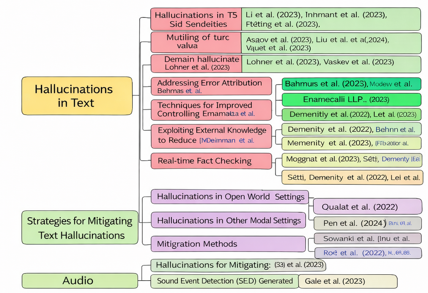
Figure 2. Taxonomy of hallucination in large foundation models, organised around detection and mitigation techniques [21].

Figure 3. LLM responses showing the types of hallucinations, highlighted in red, green, and blue [21].

Figure 4. Instances of object hallucination within LVLMs. [28]. Ground-truth objects in annotations are indicated in bold, while red objects represent hallucinated objects by LVLMs. The left case occurs in the conventional instruction-based evaluation approach, while the right case occur in three variations of POPE [21].

Figure 5. A video featuring descriptions generated by VLTinT model and ground truth (GT) with description errors highlighted in red. (Chuang and Fazli, 2023).

Figure 6. Audio hallucination examples for each class- Type A: Involving hallucinations of both objects and actions: Type B: featuring accurate objects but hallucinated actions; Type C: Displaying correct actions but hallucinated objects. (Nishimura et al., 2024).
Information

